
model {
lambda ~ multi_normal(meanLambda, covLambda); // Prior for item discrimination/factor loadings
mu ~ multi_normal(meanMu, covMu); // Prior for item intercepts
psi ~ exponential(psiRate); // Prior for unique standard deviations
theta ~ normal(0, 1); // Prior for latent variable (with mean/sd specified)
for (item in 1:nItems){
Y[,item] ~ normal(mu[item] + lambda[item]*theta, psi[item]);
}
}Generalized Measurement Models: Modeling Observed Data
Lecture 4b
Today’s Lecture Objectives
- Show different modeling specifications for different types of item response data
- Show how parameterization differs for standardized latent variables vs. marker item scale identification
Example Data: Conspiracy Theories
Today’s example is from a bootstrap resample of 177 undergraduate students at a large state university in the Midwest. The survey was a measure of 10 questions about their beliefs in various conspiracy theories that were being passed around the internet in the early 2010s. Additionally, gender was included in the survey. All items responses were on a 5- point Likert scale with:
- Strongly Disagree
- Disagree
- Neither Agree or Disagree
- Agree
- Strongly Agree
Please note, the purpose of this survey was to study individual beliefs regarding conspiracies. The questions can provoke some strong emotions given the world we live in currently. All questions were approved by university IRB prior to their use.
Our purpose in using this instrument is to provide a context that we all may find relevant as many of these conspiracy theories are still prevalent today.
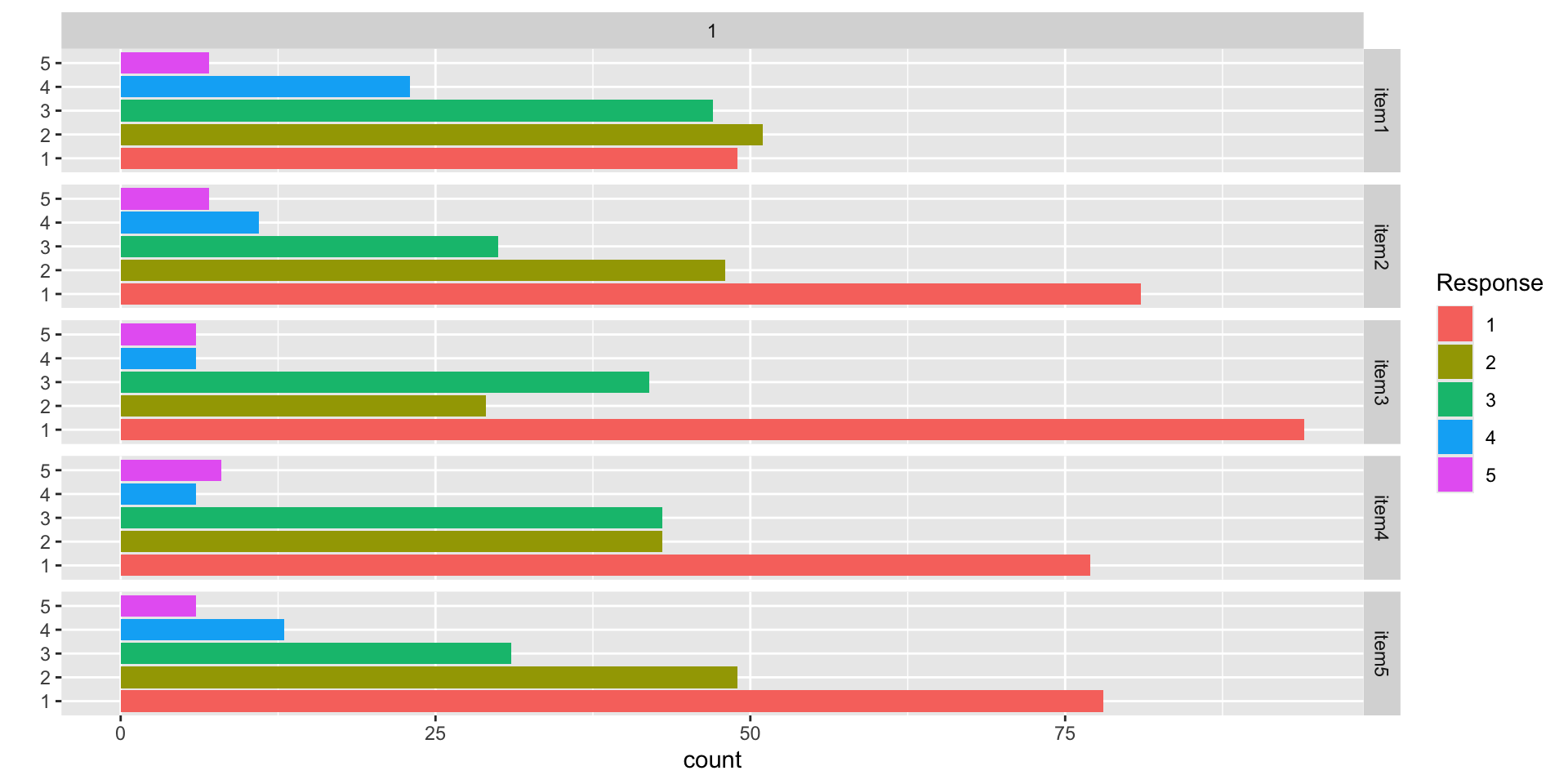
Conspiracy Theory Questions 1-5
Questions:
- The U.S. invasion of Iraq was not part of a campaign to fight terrorism, but was driven by oil companies and Jews in the U.S. and Israel.
- Certain U.S. government officials planned the attacks of September 11, 2001 because they wanted the United States to go to war in the Middle East.
- President Barack Obama was not really born in the United States and does not have an authentic Hawaiian birth certificate.
- The current financial crisis was secretly orchestrated by a small group of Wall Street bankers to extend the power of the Federal Reserve and further their control of the world’s economy.
- Vapor trails left by aircraft are actually chemical agents deliberately sprayed in a clandestine program directed by government officials.
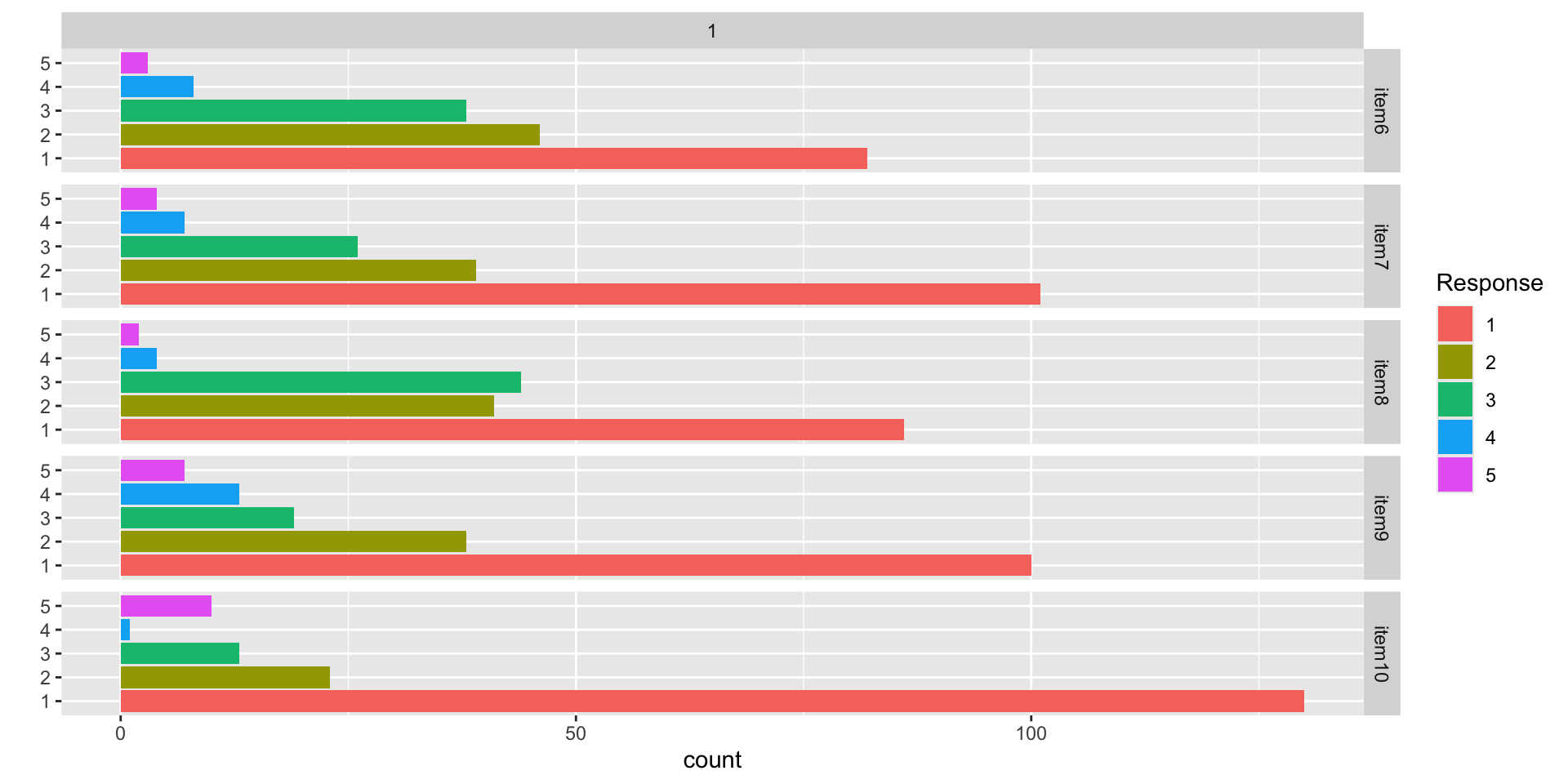
Conspiracy Theory Questions 6-10
Questions:
- Billionaire George Soros is behind a hidden plot to destabilize the American government, take control of the media, and put the world under his control.
- The U.S. government is mandating the switch to compact fluorescent light bulbs because such lights make people more obedient and easier to control.
- Government officials are covertly Building a 12-lane "NAFTA superhighway" that runs from Mexico to Canada through America’s heartland.
- Government officials purposely developed and spread drugs like crack-cocaine and diseases like AIDS in order to destroy the African American community.
- God sent Hurricane Katrina to punish America for its sins.
Data Visualization: Q1-Q5
Data Visualization: Q6-Q10
Conspiracy Theories: Assumed Latent Variable
For today’s lecture, we will assume each of the 10 items measures a single latent variable representing a person’s tendency to believe in conspiracy theories
- We will denote this latent variable as \(\theta_p\) for each person
- \(p\) is the index for person (with \(p=1, \ldots, P\))
- We will assume this latent variable is:
- Continuous
- Normally distributed: \(\theta_p \sim N\left(\mu_\theta, \sigma_\theta \right)\)
- We will make differing assumptions about the scale (the latent variable mean and standard deviation) to show how syntax works for either
- Across all people, we will denote the set of vector of latent variables as
\[\boldsymbol{\Theta} = \left[\theta_1, \ldots, \theta_P \right]^T \]
Building Measurement Models
Measurement Model Analysis Steps
- Specify model
- Specify scale identification method for latent variables
- Estimate model
- Examine model-data fit
- Iterate between steps 1-4 until adequate fit is achieved
Measurement Model Auxiliary Components
- Score estimation (and secondary analyses with scores)
- Item evaluation
- Scale construction
- Equating
- Measurement invariance/differential item functioning
Modeling Observed Variables with Normal Distributions
Observed Variables with Normal Distributions
A psychometric model posits that one or more hypothesized latent variables predict a person’s response to observed items
- Our hypothesized latent variable: Tendency to Believe in Conspiracies (\(\theta_p\))
- One variable: Unidimensional
- Each observed variable (item response) is included in the model
- Today, we will assume each response follows a normal distribution
- This is the assumption underlying confirmatory factor analysis (CFA) models
- This assumption is tenuous at best
Normal Distribution: Linear Regression
As we saw in linear models, when an outcome variable (here \(Y_p\)) is assumed to follow a (conditional) normal distribution, this places a linear regression-style model on the outcome:
For example, take the following linear regression: \[Y_p = \beta_0 + \beta_1 X_p + e_p,\] with \(e_p \sim N\left(0, \sigma_e \right)\)
This implies:
\[ Y_p \sim N\left(\beta_0 + \beta_1 X_p, \sigma_e \right)\]
Where:
- The (conditional) mean of \(Y_p\) is \(\beta_0 + \beta_1 X_p\)
- The (residual) standard deviation of \(Y_p\) is \(\sigma_e\)
The Psychometric Model
For the psychometric model:
- We replace the observed variable \(X_p\) with the latent variable \(\theta_p\) (for all observed variables)
\[ \begin{array}{cc} Y_{p1} = \mu_1 + \lambda_1 \theta_p + e_{p, 1}; & e_{p,1} \sim N\left(0, \psi_1^2 \right) \\ Y_{p2} = \mu_2 + \lambda_2 \theta_p + e_{p, 2}; & e_{p,2} \sim N\left(0, \psi_2^2 \right) \\ Y_{p3} = \mu_3 + \lambda_3 \theta_p + e_{p, 3}; & e_{p,3} \sim N\left(0, \psi_3^2 \right) \\ Y_{p4} = \mu_4 + \lambda_4 \theta_p + e_{p, 4}; & e_{p,4} \sim N\left(0, \psi_4^2 \right) \\ Y_{p5} = \mu_5 + \lambda_5 \theta_p + e_{p, 5}; & e_{p,5} \sim N\left(0, \psi_5^2 \right) \\ Y_{p6} = \mu_6 + \lambda_6 \theta_p + e_{p, 6}; & e_{p,6} \sim N\left(0, \psi_6^2 \right) \\ Y_{p7} = \mu_7 + \lambda_7 \theta_p + e_{p, 7}; & e_{p,7} \sim N\left(0, \psi_7^2 \right) \\ Y_{p8} = \mu_8 + \lambda_8 \theta_p + e_{p, 8}; & e_{p,8} \sim N\left(0, \psi_8^2 \right) \\ Y_{p9} = \mu_9 + \lambda_9 \theta_p + e_{p, 9}; & e_{p,9} \sim N\left(0, \psi_9^2 \right) \\ Y_{p10} = \mu_{10} + \lambda_{10} \theta_p + e_{p, 10}; & e_{p,10} \sim N\left(0, \psi_{10}^2 \right) \\ \end{array} \]
Measurement Model Parameters
For an item \(i\) the model is:
\[ \begin{array}{cc} Y_{pi} = \mu_i + \lambda_i \theta_p + e_{p,i}; & e_{p,i} \sim N\left(0, \psi_i^2 \right) \\ \end{array} \] The parameters of the model use different notation from typical linear regression models and have different names (they are called item parameters)
- \(\mu_i\): Item intercept
- The expected score on the item when \(\theta_p = 0\)
- Similar to \(\beta_0\)
- \(\lambda_i\): Factor loading or item discrimination
- The change in the expected score of an item for a one-unit increase in \(\theta_p\)
- Similar to \(\beta_1\)
- \(\psi^2_i\): Unique variance (Note: In Stan, we will have to specify \(\psi_e\); the unique standard deviation)
- The variance of the residuals (the expected score minus observed score)
- Similar to residual variance \(\sigma^2_e\)
Model Specification
The set of equations on the previous slide formed step #1 of the Measurement Model Analysis Steps:
- Specify Model
The next step is:
- Specify scale identification method for latent variables
We will initially assume \(\theta_p \sim N(0,1)\), which allows us to estimate all item parameters of the model
- This is what we call a standardized latent variable
- They are like Z-scores
Implementing Normal Outcomes in Stan
Implementing Normal Outcomes in Stan
There are a few changes needed to make Stan estimate psychometric models with normal outcomes:
- The model (predictor) matrix cannot be used
- This is because the latent variable will be sampled–so the model matrix cannot be formed as a constant
- The data will be imported as a matrix
- More than one outcome means more than one column vector of data
- The parameters will be specified as vectors of each type
- Each item will have its own set of parameters
- Implications for the use of prior distributions
Stan’s model Block
The loop here conducts the model, separately, for each item
- Assumption of conditional independence enables this
- Non-independence would need multivariate normal model
- The item mean is set by the conditional mean of the model
- The item SD is set by the unique variance parameter
- The loop puts each item’s parameters into the equation
Stan’s parameters {} Block
parameters {
vector[nObs] theta; // the latent variables (one for each person)
vector[nItems] mu; // the item intercepts (one for each item)
vector[nItems] lambda; // the factor loadings/item discriminations (one for each item)
vector<lower=0>[nItems] psi; // the unique standard deviations (one for each item)
}Here, the parameterization of \(\lambda\) (factor loadings/discrimination parameters) can lead to problems in estimation
- The issue: \(\lambda_i \theta_p = (-\lambda_i)(-\theta_p)\)
- Depending on the random starting values of each of these parameters (per chain), a given chain may converge to a different region
- To demonstrate (later), we will start with a different random number seed
- Currently using 09102022: works fine
- Change to 25102022: big problems
- Our fix will be to set starting values for all \(\lambda_i\) and \(\theta_p\)
Stan’s data {} Block
data {
int<lower=0> nObs; // number of observations
int<lower=0> nItems; // number of items
matrix[nObs, nItems] Y; // item responses in a matrix
vector[nItems] meanMu;
matrix[nItems, nItems] covMu; // prior covariance matrix for coefficients
vector[nItems] meanLambda; // prior mean vector for coefficients
matrix[nItems, nItems] covLambda; // prior covariance matrix for coefficients
vector[nItems] psiRate; // prior rate parameter for unique standard deviations
}Choosing Prior Distributions for Parameters
There is not uniform agreement about the choices of prior distributions for item parameters
- We will use uninformative priors on each to begin
- After first model analysis, we will discuss these choices and why they were made
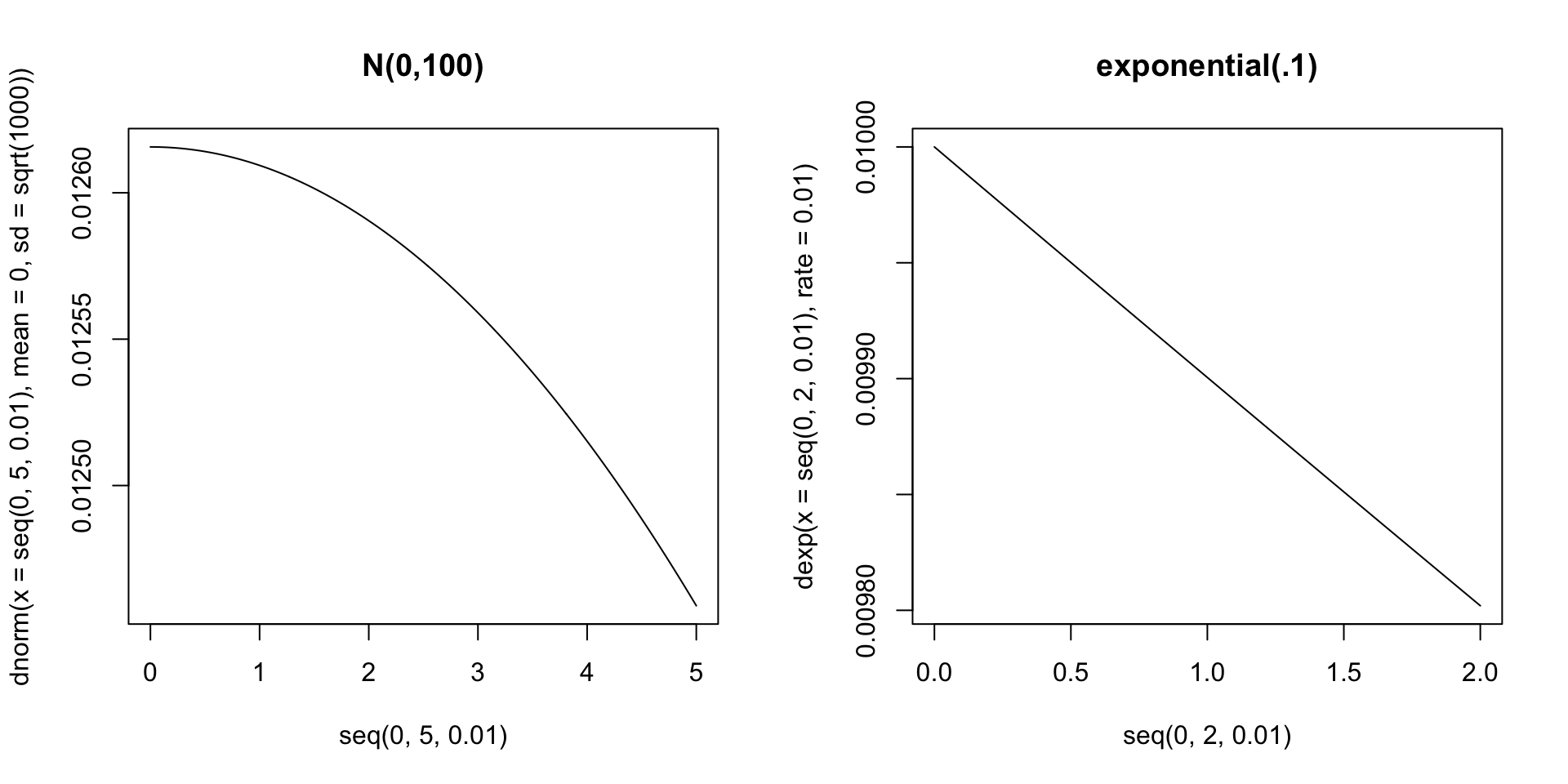
- For now:
- Item intercepts: \(\mu_i \sim N\left(0, \sigma^2_{\mu_i} = 1000\right)\)
- Factor loadings/item discriminations: \(\lambda_i \sim N(0, \sigma^2_{\lambda_i} = 1000)\)
- Unique standard deviations: \(\psi_i \sim \text{exponential}\left(.01\right)\)
Prior Density Function Plots
R’s Data List Object
# data dimensions
nObs = nrow(conspiracyItems)
nItems = ncol(conspiracyItems)
# item intercept hyperparameters
muMeanHyperParameter = 0
muMeanVecHP = rep(muMeanHyperParameter, nItems)
muVarianceHyperParameter = 1000
muCovarianceMatrixHP = diag(x = muVarianceMatrixHP, nrow = nItems)
# item discrimination/factor loading hyperparameters
lambdaMeanHyperParameter = 0
lambdaMeanVecHP = rep(lambdaMeanHyperParameter, nItems)
lambdaVarianceHyperParameter = 1000
lambdaCovarianceMatrixHP = diag(x = lambdaVarianceHyperParameter, nrow = nItems)
# unique standard deviation hyperparameters
psiRateHyperParameter = .01
psiRateVecHP = rep(.1, nItems)
modelCFA_data = list(
nObs = nObs,
nItems = nItems,
Y = conspiracyItems,
meanMu = muMeanVecHP,
covMu = muCovarianceMatrixHP,
meanLambda = lambdaMeanVecHP,
covLambda = lambdaCovarianceMatrixHP,
psiRate = psiRateVecHP
)Running the Model In Stan
The Stan program takes longer to run than in linear models:
- Number of parameters = 207
- 10 observed variables (with three item parameters each: \(\mu_i\), \(\lambda_i\), and \(\psi_i\))
- 177 latent variables (one for each person: 177 parameters)
- cmdstanr samples call:
- Note: Typically, longer chains are needed for larger models like this
- These will become even longer when we use non-normal distributions for observed data
Stan’s init Option
- The
initoption is used to set starting values for the parameters- This is especially important for the item discrimination parameters \(\lambda_i\) and the latent variables \(\theta_p\)
- This code tells Stan to sample starting values for \(\lambda_i\) from a normal distribution with mean 10 and standard deviation 2
- This ensures starting values for \(\lambda_i\) will most likely be positive
- For \(\theta_p\), we will need more work…
Initializing Latent Variables
As we expect the latent variable to be highly related to the sum score, we can use the sum score to help us initialize \(\theta_p\) so we end up in the correct mode of the posterior distribution
We will use the standardized sum score as a starting value for \(\theta_p\) (starting value denoted \(\theta_p^*\))
\[\theta_{p}^* = \frac{\sum_{i=1}^I Y_{pi} - \text{mean}\left({\sum_{i=1}^I Y_{pi}}\right)}{\text{sd}\left({\sum_{i=1}^I Y_{pi}}\right)}\]
- We will use the standardized sum score as the starting value for \(\theta_p\) in the
initoption- In my example, I set the standard deviation of the normal distribution to zero (meaning the function just returns the mean) – you can also choose to make this a small value allowing for some variability
Model Results
- Checking convergence with \(\hat{R}\) (PSRF):
[1] 1.005758- Item Parameter Results:
# A tibble: 30 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu[1] 2.37 2.37 0.0862 0.0863 2.23 2.51 1.00 1369. 2860.
2 mu[2] 1.96 1.96 0.0840 0.0832 1.82 2.09 1.00 975. 2023.
3 mu[3] 1.88 1.88 0.0842 0.0816 1.74 2.02 1.00 1103. 2563.
4 mu[4] 2.01 2.01 0.0838 0.0824 1.87 2.15 1.00 1050. 2438.
5 mu[5] 1.98 1.98 0.0840 0.0847 1.85 2.12 1.00 759. 1309.
6 mu[6] 1.89 1.90 0.0754 0.0747 1.77 2.02 1.00 773. 1532.
7 mu[7] 1.72 1.73 0.0759 0.0758 1.60 1.85 1.00 1108. 2316.
8 mu[8] 1.84 1.84 0.0716 0.0707 1.73 1.96 1.00 759. 1476.
9 mu[9] 1.81 1.81 0.0867 0.0858 1.66 1.95 1.00 1055. 2163.
10 mu[10] 1.52 1.52 0.0814 0.0814 1.39 1.65 1.00 1414. 3088.
11 lambda[1] 0.739 0.738 0.0825 0.0812 0.607 0.877 1.00 2492. 4852.
12 lambda[2] 0.871 0.870 0.0778 0.0775 0.746 1.00 1.00 1692. 3480.
13 lambda[3] 0.804 0.802 0.0779 0.0774 0.677 0.932 1.00 2056. 3944.
14 lambda[4] 0.844 0.842 0.0774 0.0776 0.721 0.974 1.00 1716. 3324.
15 lambda[5] 0.999 0.996 0.0723 0.0726 0.883 1.12 1.01 1126. 2516.
16 lambda[6] 0.900 0.896 0.0657 0.0675 0.797 1.01 1.00 1111. 2967.
17 lambda[7] 0.765 0.763 0.0702 0.0700 0.653 0.884 1.00 1731. 3725.
18 lambda[8] 0.854 0.853 0.0617 0.0631 0.756 0.958 1.00 1102. 2455.
19 lambda[9] 0.862 0.861 0.0801 0.0801 0.734 0.995 1.00 1767. 3832.
20 lambda[10] 0.673 0.671 0.0774 0.0767 0.548 0.800 1.00 2536. 4138.
21 psi[1] 0.891 0.888 0.0518 0.0517 0.810 0.980 1.00 15383. 5995.
22 psi[2] 0.734 0.732 0.0429 0.0431 0.667 0.808 1.00 12105. 6396.
23 psi[3] 0.783 0.781 0.0442 0.0439 0.714 0.857 1.00 15176. 6273.
24 psi[4] 0.758 0.756 0.0438 0.0431 0.689 0.834 1.00 13862. 5865.
25 psi[5] 0.545 0.543 0.0371 0.0362 0.487 0.610 1.00 9358. 6936.
26 psi[6] 0.505 0.504 0.0332 0.0334 0.452 0.562 1.00 8442. 6312.
27 psi[7] 0.687 0.685 0.0401 0.0399 0.624 0.755 1.00 14397. 6500.
28 psi[8] 0.480 0.479 0.0318 0.0319 0.429 0.534 1.00 9040. 6473.
29 psi[9] 0.782 0.780 0.0452 0.0443 0.711 0.860 1.00 14683. 6355.
30 psi[10] 0.840 0.838 0.0469 0.0468 0.766 0.920 1.00 15456. 5393.Modeling Strategy vs. Didactic Strategy
At this point, one should investigate model fit of the model we just ran
- If the model does not fit, then all model parameters could be biased
- Both item parameters and person parameters (\(\theta_p\))
- Moreover, the uncertainty accompanying each parameter (the posterior standard deviation) may also be biased
- Especially bad for psychometric models as we quantify reliaiblity with these numbers
But, to teach generalized measurement models, we will first talk about differing models for observed data
- Different distributions
- Different parameterizations across the different distributions
Then we will discuss model fit methods
Investigating Item Parameters
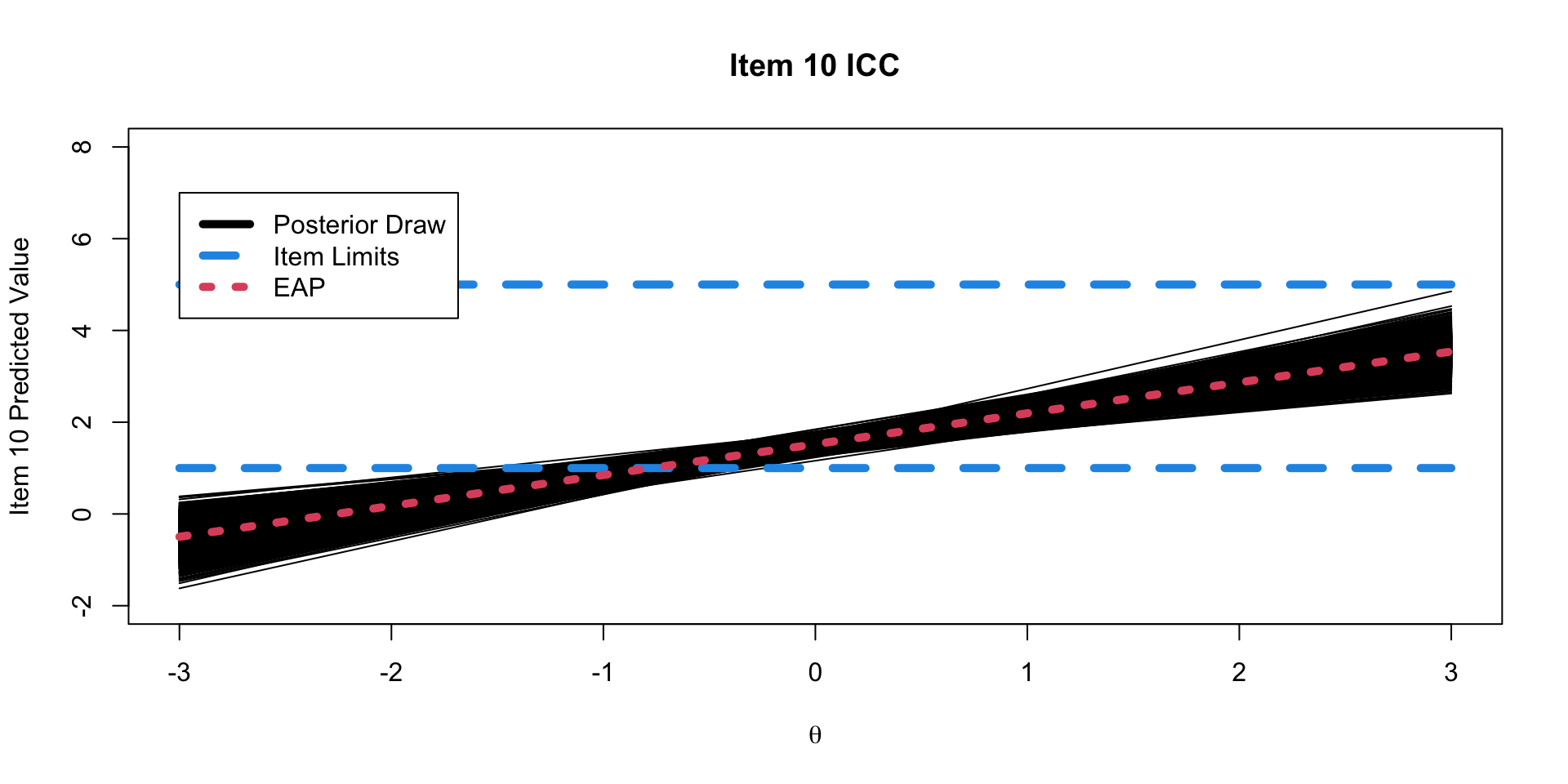
One plot that can help provide information about the item parameters is the item characteristic curve (ICC)
- Not called this in CFA (but equivalent)
- The ICC is the plot of the expected value of the response conditional on the value of the latent traits, for a range of latent trait values
\[E \left(Y_{pi} \mid \theta_p \right) = \mu_{i} +\lambda_{i}\theta_p \]
- Because we have sampled values for each parameter, we can plot one ICC for each posterior draw
Posterior ICC Plots
Posterior Distribution for Item Parameters
Before moving onto the latent variables, let’s note the posterior distribution of the item parameters (for a single item):
\[f(\mu_i, \lambda_i, \psi_i \mid \boldsymbol{Y}) \propto f\left(\boldsymbol{Y} \mid \mu_i, \lambda_i, \psi_i \right) f\left(\mu_i, \lambda_i, \psi_i \right) \]
\(f(\mu_i, \lambda_i, \psi_i \mid \boldsymbol{Y})\) is the (joint) posterior distribution of the parameters for item \(i\)
- The distribution of the parameters conditional on the data
\(f\left(\boldsymbol{Y} \mid \mu_i, \lambda_i, \psi_i \right)\) is the distribution we defined for our observed data:
\[ f\left(\boldsymbol{Y} \mid \mu_i, \lambda_i, \psi_i \right) \sim N \left(\mu_i+\lambda_i\theta_p, \psi_i \right)\]
\(f\left(\mu_i, \lambda_i, \psi_i \right)\) is the (joint) prior distribution for each of the parameters, which, are independent:
\[ f\left(\mu_i, \lambda_i, \psi_i \right) = f(\mu_i)f(\lambda_i)f(\psi_i)\]
Investigating the Latent Variables
The estimated latent variables are then:
# A tibble: 177 × 10
variable mean median sd mad q5 q95 rhat ess_bulk
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 theta[1] 0.0149 0.0176 0.249 0.249 -0.399 0.425 1.00 5825.
2 theta[2] 1.52 1.52 0.260 0.261 1.10 1.96 1.00 4026.
3 theta[3] 1.70 1.69 0.262 0.265 1.28 2.14 1.00 3119.
4 theta[4] -0.930 -0.924 0.250 0.250 -1.34 -0.529 1.00 4175.
5 theta[5] 0.0402 0.0388 0.248 0.249 -0.364 0.449 1.00 5522.
6 theta[6] -0.982 -0.983 0.244 0.246 -1.39 -0.585 1.00 3629.
7 theta[7] -0.340 -0.339 0.250 0.251 -0.752 0.0644 1.00 4861.
8 theta[8] -0.0576 -0.0579 0.251 0.246 -0.473 0.357 1.00 5262.
9 theta[9] -0.791 -0.789 0.247 0.245 -1.20 -0.392 1.00 4166.
10 theta[10] 0.0404 0.0399 0.243 0.247 -0.358 0.435 1.00 4842.
11 theta[11] -0.984 -0.982 0.250 0.247 -1.40 -0.580 1.00 3779.
12 theta[12] 0.252 0.250 0.246 0.247 -0.147 0.661 1.00 4963.
13 theta[13] -0.751 -0.748 0.251 0.247 -1.17 -0.349 1.00 4498.
14 theta[14] -0.982 -0.979 0.251 0.246 -1.40 -0.583 1.00 3831.
15 theta[15] -0.841 -0.837 0.247 0.246 -1.26 -0.442 1.00 4289.
16 theta[16] -0.0692 -0.0707 0.249 0.244 -0.478 0.347 1.00 5734.
17 theta[17] -0.0684 -0.0688 0.245 0.242 -0.467 0.333 1.00 4837.
18 theta[18] -0.668 -0.669 0.251 0.253 -1.08 -0.259 1.00 4203.
19 theta[19] 1.86 1.86 0.274 0.274 1.41 2.32 1.00 3063.
20 theta[20] -0.929 -0.926 0.248 0.250 -1.34 -0.519 1.00 4091.
21 theta[21] -0.256 -0.255 0.243 0.234 -0.660 0.143 1.00 4999.
22 theta[22] -0.981 -0.980 0.251 0.250 -1.39 -0.575 1.00 4520.
23 theta[23] -0.980 -0.979 0.254 0.251 -1.41 -0.574 1.00 3956.
24 theta[24] -0.979 -0.975 0.254 0.252 -1.40 -0.563 1.00 3853.
25 theta[25] 0.540 0.537 0.252 0.250 0.129 0.953 1.00 5490.
26 theta[26] 0.730 0.728 0.253 0.245 0.322 1.15 1.00 4504.
27 theta[27] -0.118 -0.120 0.252 0.256 -0.533 0.290 1.00 4609.
28 theta[28] 1.21 1.20 0.247 0.249 0.807 1.62 1.00 3842.
29 theta[29] 0.886 0.885 0.247 0.247 0.480 1.30 1.00 4142.
30 theta[30] 1.67 1.67 0.266 0.263 1.24 2.12 1.00 3570.
31 theta[31] 0.538 0.538 0.249 0.239 0.128 0.950 1.00 4646.
32 theta[32] -0.418 -0.416 0.255 0.250 -0.842 0.00117 1.00 5898.
33 theta[33] 0.318 0.316 0.245 0.244 -0.0737 0.725 1.00 5098.
34 theta[34] -0.981 -0.978 0.246 0.245 -1.38 -0.576 1.00 3805.
35 theta[35] -0.668 -0.666 0.254 0.255 -1.09 -0.257 1.00 5079.
36 theta[36] -0.796 -0.796 0.245 0.244 -1.20 -0.399 1.00 4946.
37 theta[37] -0.983 -0.985 0.246 0.245 -1.39 -0.577 1.00 3900.
38 theta[38] -0.220 -0.223 0.251 0.244 -0.633 0.201 1.00 5376.
39 theta[39] -0.983 -0.983 0.256 0.253 -1.40 -0.561 1.00 4032.
40 theta[40] 0.0409 0.0390 0.244 0.243 -0.363 0.446 1.00 6828.
41 theta[41] -0.982 -0.977 0.253 0.249 -1.40 -0.571 1.00 3616.
42 theta[42] -0.0907 -0.0887 0.250 0.252 -0.500 0.309 1.00 5692.
43 theta[43] -0.647 -0.645 0.244 0.252 -1.05 -0.252 1.00 4414.
44 theta[44] -0.0711 -0.0723 0.246 0.239 -0.473 0.338 1.00 5027.
45 theta[45] 0.376 0.378 0.248 0.247 -0.0402 0.782 1.00 5562.
46 theta[46] 0.262 0.264 0.245 0.242 -0.141 0.667 1.00 6349.
47 theta[47] 0.502 0.500 0.253 0.252 0.0882 0.918 1.00 5547.
48 theta[48] -0.838 -0.834 0.242 0.241 -1.25 -0.443 1.00 4463.
49 theta[49] -0.982 -0.981 0.251 0.246 -1.40 -0.581 1.00 3723.
50 theta[50] 0.156 0.160 0.251 0.247 -0.257 0.572 1.00 5491.
51 theta[51] -0.983 -0.979 0.247 0.240 -1.40 -0.578 1.00 3752.
52 theta[52] 0.316 0.316 0.251 0.253 -0.0926 0.730 1.00 5573.
53 theta[53] -0.980 -0.977 0.256 0.254 -1.40 -0.566 1.00 4192.
54 theta[54] 1.21 1.21 0.259 0.261 0.783 1.64 1.00 3868.
55 theta[55] -0.980 -0.979 0.254 0.249 -1.40 -0.567 1.00 3677.
56 theta[56] -0.980 -0.976 0.249 0.248 -1.40 -0.578 1.00 4091.
57 theta[57] -0.735 -0.731 0.251 0.247 -1.15 -0.322 1.00 4310.
58 theta[58] -0.980 -0.978 0.250 0.248 -1.39 -0.573 1.00 4210.
59 theta[59] -0.0752 -0.0751 0.243 0.246 -0.479 0.331 1.00 4562.
60 theta[60] -0.647 -0.643 0.242 0.240 -1.05 -0.255 1.00 4092.
61 theta[61] 1.38 1.37 0.260 0.263 0.955 1.81 1.00 3670.
62 theta[62] 0.318 0.320 0.243 0.238 -0.0793 0.729 1.00 5113.
63 theta[63] -0.979 -0.978 0.247 0.248 -1.39 -0.573 1.00 4373.
64 theta[64] 1.37 1.36 0.255 0.254 0.961 1.80 1.00 3946.
65 theta[65] 1.20 1.20 0.248 0.245 0.804 1.62 1.00 4040.
66 theta[66] -0.754 -0.754 0.249 0.253 -1.16 -0.347 1.00 4548.
67 theta[67] 0.539 0.537 0.249 0.251 0.128 0.956 1.00 5174.
68 theta[68] 0.851 0.850 0.250 0.246 0.444 1.27 1.00 4489.
69 theta[69] -0.530 -0.530 0.252 0.249 -0.945 -0.115 1.00 4774.
70 theta[70] 0.885 0.882 0.251 0.247 0.473 1.31 1.00 4849.
71 theta[71] 0.0558 0.0570 0.243 0.243 -0.345 0.453 1.00 5378.
72 theta[72] 1.04 1.04 0.258 0.261 0.623 1.47 1.00 4268.
73 theta[73] -0.0178 -0.0196 0.247 0.241 -0.419 0.395 1.00 5512.
74 theta[74] -0.979 -0.977 0.251 0.250 -1.39 -0.571 1.00 4231.
75 theta[75] -0.979 -0.981 0.254 0.258 -1.39 -0.565 1.00 4405.
76 theta[76] 3.24 3.24 0.299 0.293 2.76 3.76 1.00 1839.
77 theta[77] -0.794 -0.794 0.252 0.247 -1.21 -0.378 1.00 3947.
78 theta[78] 1.14 1.14 0.250 0.246 0.742 1.56 1.00 4008.
79 theta[79] 1.86 1.86 0.274 0.273 1.42 2.32 1.00 3231.
80 theta[80] 0.608 0.604 0.250 0.245 0.196 1.02 1.00 4659.
81 theta[81] 0.0461 0.0456 0.245 0.244 -0.352 0.452 1.00 5404.
82 theta[82] 0.0186 0.0162 0.249 0.253 -0.390 0.428 1.00 4973.
83 theta[83] -0.980 -0.975 0.251 0.249 -1.39 -0.573 1.00 4115.
84 theta[84] 1.57 1.57 0.266 0.273 1.14 2.01 1.00 3701.
85 theta[85] 0.206 0.204 0.248 0.246 -0.196 0.621 1.00 5842.
86 theta[86] -0.982 -0.978 0.247 0.242 -1.40 -0.581 1.00 4084.
87 theta[87] 0.165 0.162 0.247 0.247 -0.244 0.574 1.00 5868.
88 theta[88] -0.319 -0.318 0.247 0.248 -0.732 0.0827 1.00 5772.
89 theta[89] -0.981 -0.974 0.249 0.247 -1.40 -0.578 1.00 3868.
90 theta[90] 0.833 0.833 0.249 0.248 0.433 1.25 1.00 4588.
91 theta[91] -0.838 -0.832 0.251 0.255 -1.25 -0.430 1.00 4536.
92 theta[92] 1.06 1.06 0.253 0.255 0.642 1.48 1.00 4692.
93 theta[93] 0.0168 0.0140 0.251 0.249 -0.393 0.433 1.00 5666.
94 theta[94] 2.58 2.58 0.285 0.285 2.13 3.06 1.00 2315.
95 theta[95] 1.65 1.65 0.259 0.258 1.24 2.09 1.00 3350.
96 theta[96] 0.317 0.318 0.246 0.250 -0.0874 0.720 1.00 4429.
97 theta[97] 0.262 0.260 0.247 0.245 -0.134 0.665 1.00 5927.
98 theta[98] -0.982 -0.979 0.254 0.252 -1.40 -0.567 1.00 4066.
99 theta[99] 1.21 1.20 0.249 0.247 0.806 1.62 1.00 3736.
100 theta[100] -0.931 -0.926 0.248 0.244 -1.34 -0.533 1.00 4439.
101 theta[101] -0.707 -0.706 0.245 0.243 -1.12 -0.303 1.00 3994.
102 theta[102] 2.81 2.81 0.288 0.288 2.34 3.29 1.00 2096.
103 theta[103] -0.669 -0.666 0.255 0.257 -1.09 -0.251 1.00 4065.
104 theta[104] 0.854 0.848 0.263 0.262 0.423 1.29 1.00 4669.
105 theta[105] -0.0884 -0.0870 0.251 0.250 -0.499 0.322 1.00 5462.
106 theta[106] 1.12 1.12 0.256 0.256 0.709 1.55 1.00 4583.
107 theta[107] 1.57 1.56 0.260 0.260 1.15 2.00 1.00 3379.
108 theta[108] 0.834 0.828 0.251 0.258 0.433 1.25 1.00 4598.
109 theta[109] 1.03 1.03 0.255 0.255 0.619 1.45 1.00 4562.
110 theta[110] 0.0417 0.0406 0.246 0.246 -0.360 0.448 1.00 5277.
111 theta[111] 0.112 0.112 0.245 0.244 -0.291 0.522 1.00 5637.
112 theta[112] -0.641 -0.636 0.250 0.248 -1.06 -0.232 1.00 5001.
113 theta[113] 0.370 0.363 0.246 0.249 -0.0296 0.775 1.00 5221.
114 theta[114] -0.320 -0.324 0.245 0.245 -0.720 0.0852 1.00 4778.
115 theta[115] 0.855 0.853 0.257 0.259 0.439 1.28 1.00 4557.
116 theta[116] -0.173 -0.173 0.245 0.246 -0.580 0.228 1.00 5387.
117 theta[117] 0.0605 0.0577 0.244 0.248 -0.342 0.460 1.00 5155.
118 theta[118] 0.316 0.318 0.246 0.247 -0.0939 0.713 1.00 5385.
119 theta[119] -0.838 -0.836 0.250 0.251 -1.26 -0.438 1.00 4460.
120 theta[120] -0.980 -0.979 0.253 0.256 -1.40 -0.572 1.00 4108.
121 theta[121] 0.201 0.203 0.253 0.253 -0.219 0.608 1.00 4782.
122 theta[122] -0.642 -0.641 0.246 0.246 -1.04 -0.242 1.00 4503.
123 theta[123] 1.21 1.20 0.254 0.256 0.802 1.64 1.00 3945.
124 theta[124] 1.03 1.03 0.251 0.250 0.625 1.45 1.00 4298.
125 theta[125] -0.981 -0.975 0.245 0.248 -1.39 -0.587 1.00 3647.
126 theta[126] -0.642 -0.639 0.250 0.247 -1.05 -0.238 1.00 4406.
127 theta[127] 1.12 1.12 0.257 0.254 0.711 1.56 1.00 4306.
128 theta[128] -0.850 -0.848 0.251 0.251 -1.27 -0.435 1.00 4346.
129 theta[129] -0.669 -0.668 0.251 0.248 -1.09 -0.261 1.00 4720.
130 theta[130] 1.86 1.86 0.269 0.270 1.43 2.31 1.00 3018.
131 theta[131] -0.344 -0.341 0.246 0.251 -0.744 0.0543 1.00 4973.
132 theta[132] 1.65 1.65 0.265 0.265 1.22 2.09 1.00 3304.
133 theta[133] -0.982 -0.979 0.248 0.251 -1.40 -0.584 1.00 4315.
134 theta[134] 2.59 2.58 0.281 0.285 2.14 3.06 1.00 2168.
135 theta[135] -0.794 -0.794 0.252 0.251 -1.21 -0.379 1.00 4153.
136 theta[136] -0.980 -0.978 0.246 0.241 -1.38 -0.576 1.00 4247.
137 theta[137] 0.774 0.770 0.255 0.255 0.358 1.20 1.00 5349.
138 theta[138] -0.791 -0.792 0.248 0.249 -1.19 -0.383 1.00 4357.
139 theta[139] 0.0411 0.0432 0.245 0.250 -0.359 0.442 1.00 5791.
140 theta[140] -0.0575 -0.0591 0.244 0.247 -0.461 0.343 1.00 4311.
141 theta[141] -0.842 -0.840 0.248 0.245 -1.26 -0.434 1.00 4107.
142 theta[142] -0.978 -0.976 0.252 0.253 -1.39 -0.573 1.00 3674.
143 theta[143] -0.979 -0.978 0.247 0.246 -1.38 -0.577 1.00 4143.
144 theta[144] 0.811 0.809 0.250 0.251 0.410 1.23 1.00 4573.
145 theta[145] -0.980 -0.981 0.251 0.242 -1.39 -0.568 1.00 4024.
146 theta[146] 0.610 0.606 0.246 0.249 0.208 1.01 1.00 5099.
147 theta[147] 0.852 0.852 0.253 0.252 0.437 1.27 1.00 5151.
148 theta[148] 0.112 0.108 0.255 0.254 -0.302 0.539 1.00 5024.
149 theta[149] -0.982 -0.979 0.250 0.249 -1.40 -0.576 1.00 4031.
150 theta[150] -0.978 -0.974 0.246 0.247 -1.39 -0.579 1.00 4294.
151 theta[151] -0.641 -0.637 0.254 0.255 -1.06 -0.227 1.00 5183.
152 theta[152] -0.981 -0.980 0.249 0.252 -1.39 -0.577 1.00 4164.
153 theta[153] 1.52 1.52 0.259 0.257 1.10 1.96 1.00 3673.
154 theta[154] -0.931 -0.926 0.249 0.248 -1.34 -0.530 1.00 4235.
155 theta[155] -0.981 -0.977 0.250 0.248 -1.39 -0.574 1.00 4307.
156 theta[156] -0.838 -0.836 0.254 0.255 -1.25 -0.426 1.00 4504.
157 theta[157] -0.836 -0.836 0.251 0.255 -1.25 -0.426 1.00 4324.
158 theta[158] -0.0191 -0.0208 0.244 0.250 -0.423 0.380 1.00 5119.
159 theta[159] 0.612 0.611 0.254 0.257 0.193 1.03 1.00 4876.
160 theta[160] -0.982 -0.976 0.251 0.248 -1.40 -0.574 1.00 4076.
161 theta[161] 1.29 1.29 0.251 0.250 0.880 1.71 1.00 3820.
162 theta[162] 0.168 0.171 0.252 0.246 -0.254 0.577 1.00 5447.
163 theta[163] -0.982 -0.980 0.252 0.249 -1.40 -0.572 1.00 4085.
164 theta[164] -0.544 -0.541 0.253 0.254 -0.963 -0.128 1.00 5010.
165 theta[165] 0.157 0.160 0.253 0.249 -0.262 0.573 1.00 5206.
166 theta[166] -0.985 -0.979 0.253 0.251 -1.41 -0.583 1.00 3812.
167 theta[167] 0.319 0.317 0.244 0.245 -0.0770 0.723 1.00 5024.
168 theta[168] 1.37 1.37 0.256 0.258 0.957 1.80 1.00 3813.
169 theta[169] -0.355 -0.355 0.246 0.249 -0.749 0.0526 1.00 4343.
170 theta[170] 0.112 0.111 0.244 0.244 -0.283 0.507 1.00 5181.
171 theta[171] -0.750 -0.748 0.248 0.244 -1.16 -0.340 1.00 4338.
172 theta[172] 0.199 0.199 0.242 0.242 -0.197 0.596 1.00 5408.
173 theta[173] 0.607 0.607 0.250 0.250 0.200 1.02 1.00 5023.
174 theta[174] -0.711 -0.708 0.247 0.247 -1.12 -0.309 1.00 4031.
175 theta[175] -0.669 -0.668 0.250 0.251 -1.08 -0.263 1.00 4523.
176 theta[176] -0.791 -0.786 0.247 0.246 -1.20 -0.392 1.00 4259.
177 theta[177] -0.437 -0.437 0.255 0.251 -0.859 -0.0222 1.00 5909.
# ℹ 1 more variable: ess_tail <dbl>EAP Estimates of Latent Variables
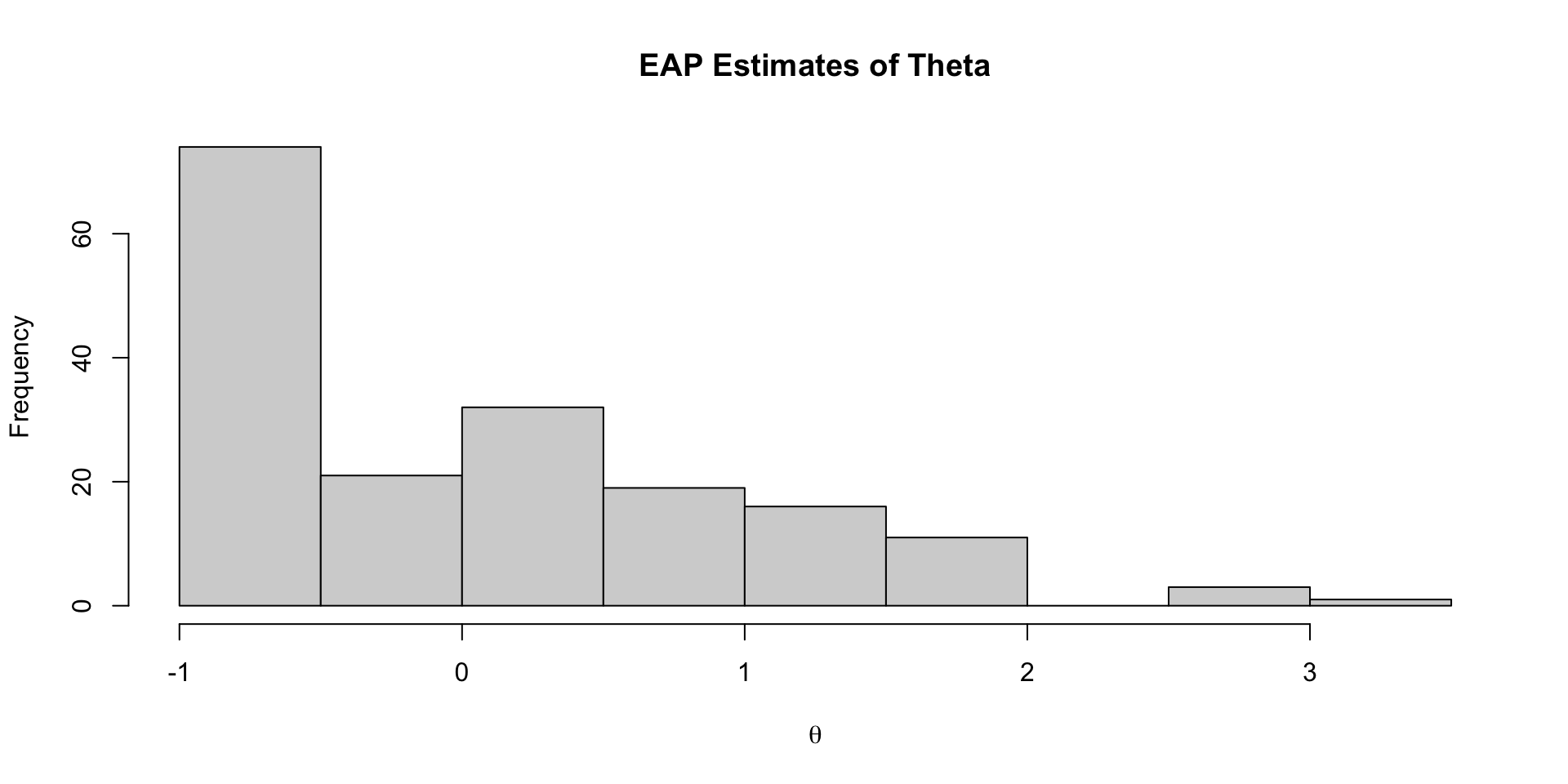
Density of EAP Estimates
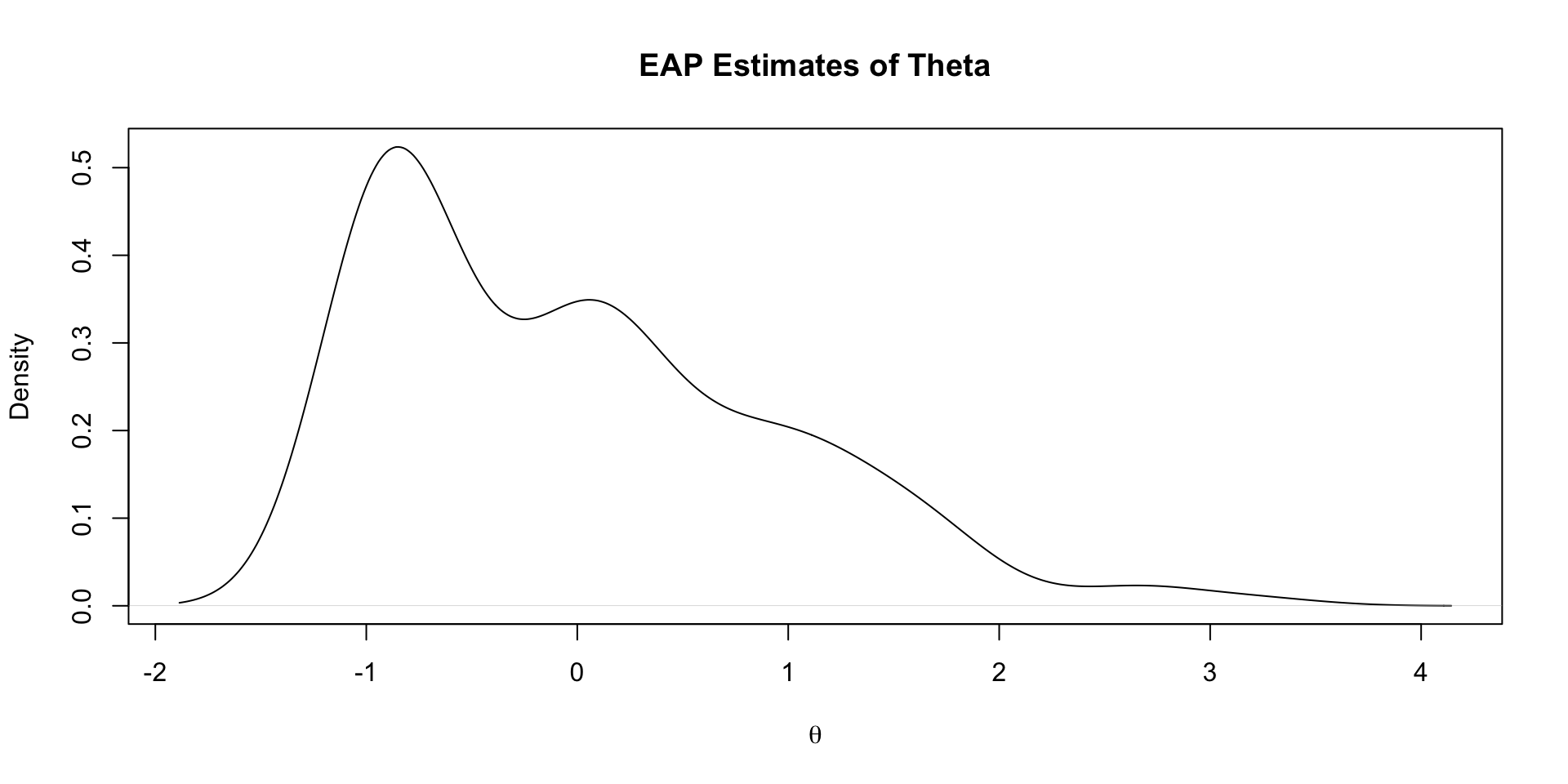
Density of All Posterior Draws
Comparing Two Posterior Distributions
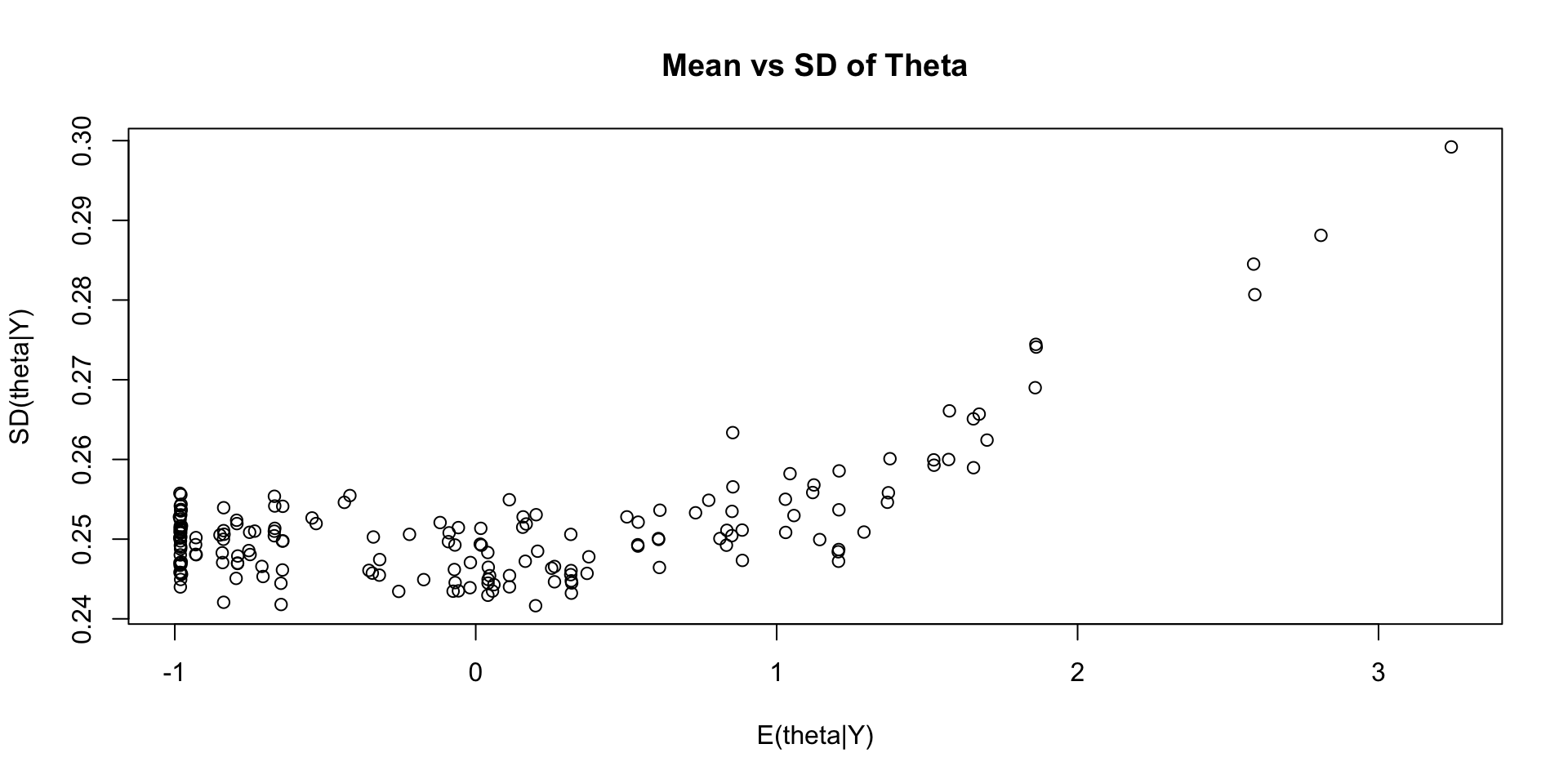
Comparing EAP Estimate with Posterior SD
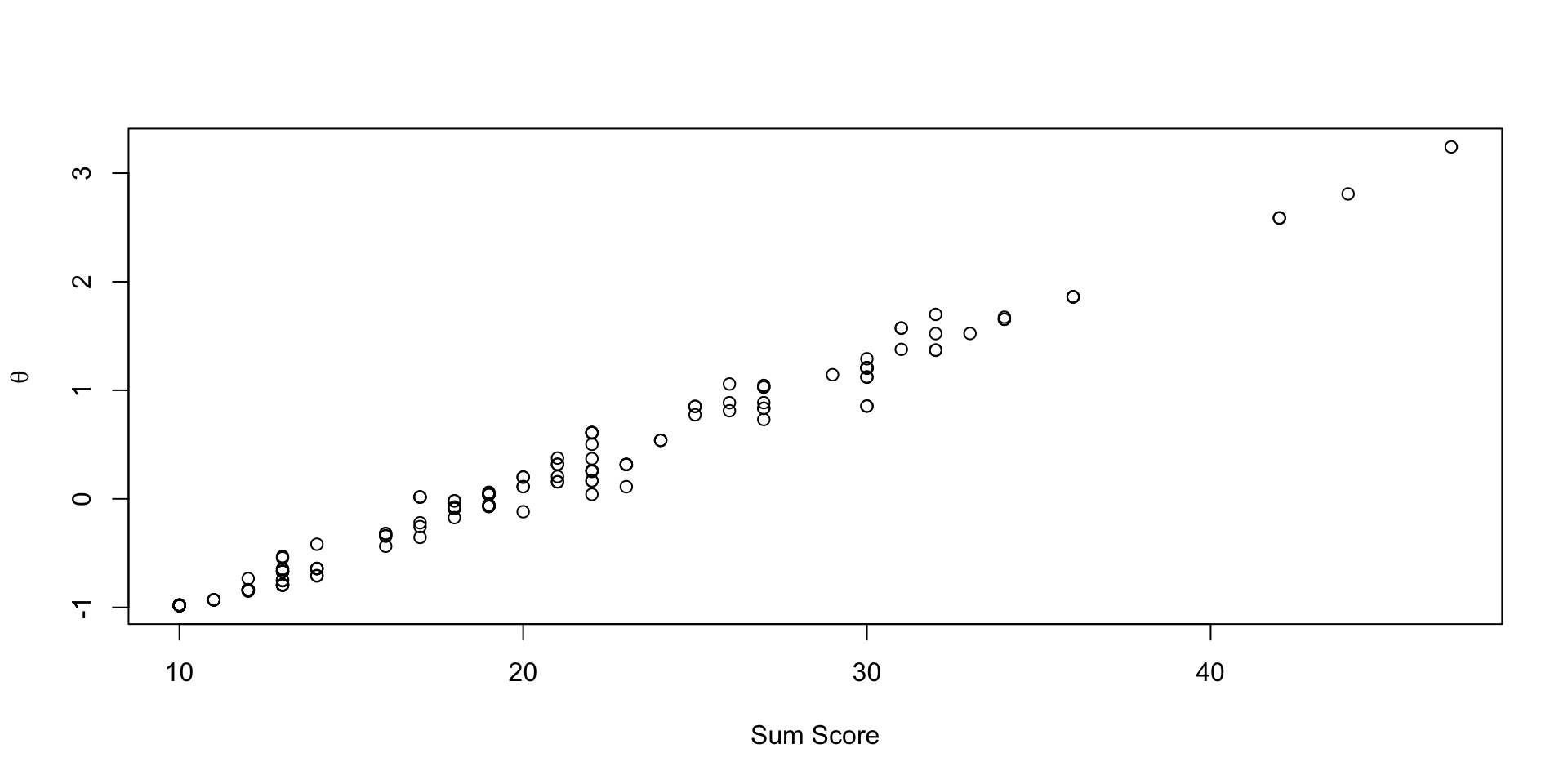
Comparing EAP Estimate with Sum Score
Posterior Distribution for Person Parameters
The posterior distribution of the person parameters (the latent variable; for a single person): \[ f(\theta_p \mid \boldsymbol{Y}) \propto f\left(\boldsymbol{Y} \mid \theta_p \right) f\left(\theta_p \right) \]
Here:
- \(f(\theta_p \mid \boldsymbol{Y})\) is the posterior distribution of the latent variable conditional on the observed data
- \(f\left(\boldsymbol{Y} \mid \theta_p \right)\) is the model (data) likelihood
\[ f\left(\boldsymbol{Y} \mid \theta_p \right) = \prod_{i=1}^I f(Y_i \mid \theta_p)\]
- \(f(Y_i \mid \theta_p)\) is the observed data likelihood: \(f(Y_i \mid \theta_p) \sim N(\mu_i + \lambda_i\theta_p, \psi_i)\)
- \(f\left(\theta_p \right) \sim N(0,1)\) is the prior likelihood for the latent variable \(\theta_p\)
- Technical details: https://jonathantemplin.com/wp-content/uploads/2022/10/sem15pre906_lecture11.pdf
Measurement Model Estimation Fails
Recall: Stan’s parameters {} Block
parameters {
vector[nObs] theta; // the latent variables (one for each person)
vector[nItems] mu; // the item intercepts (one for each item)
vector[nItems] lambda; // the factor loadings/item discriminations (one for each item)
vector<lower=0>[nItems] psi; // the unique standard deviations (one for each item)
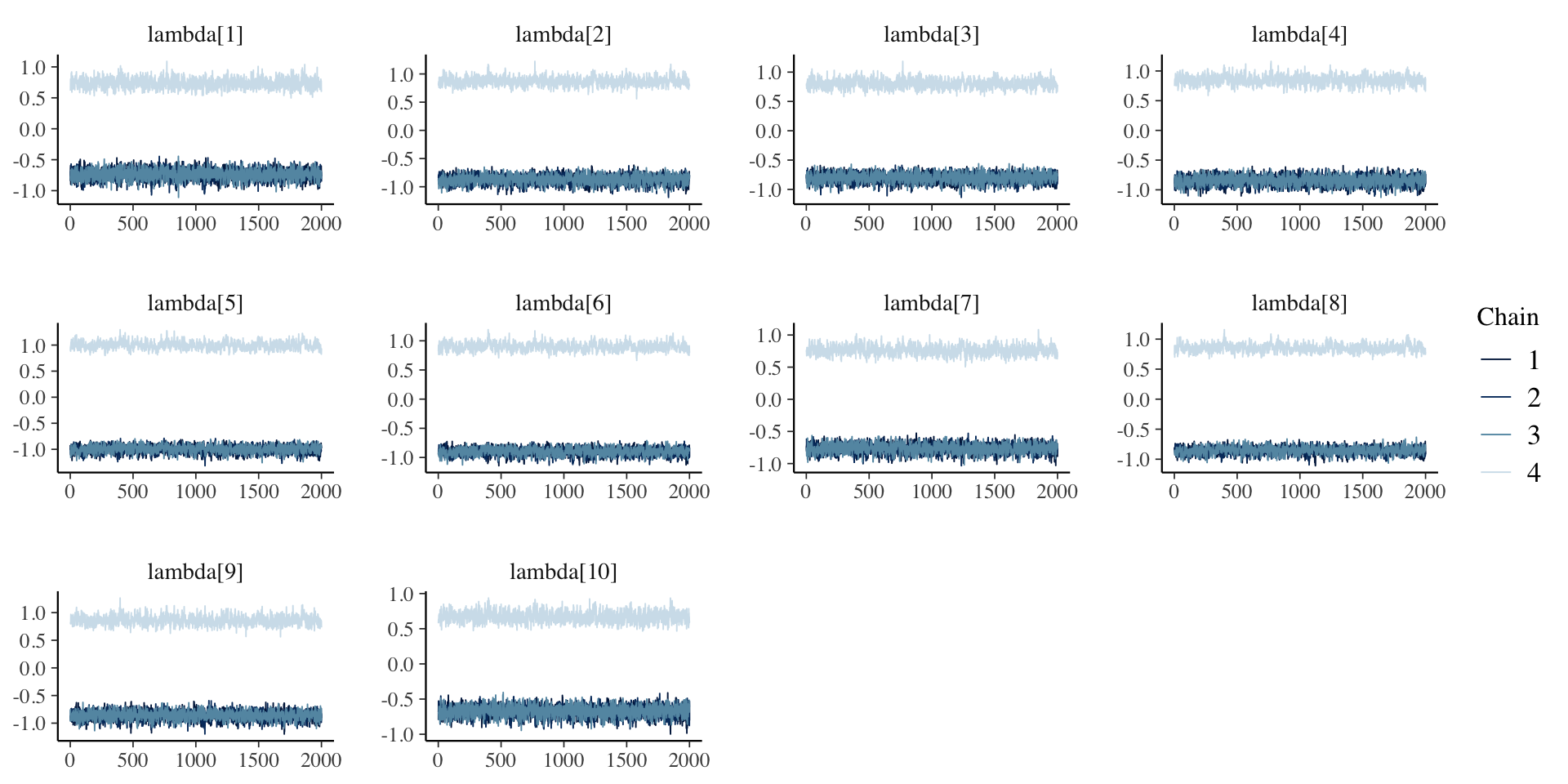
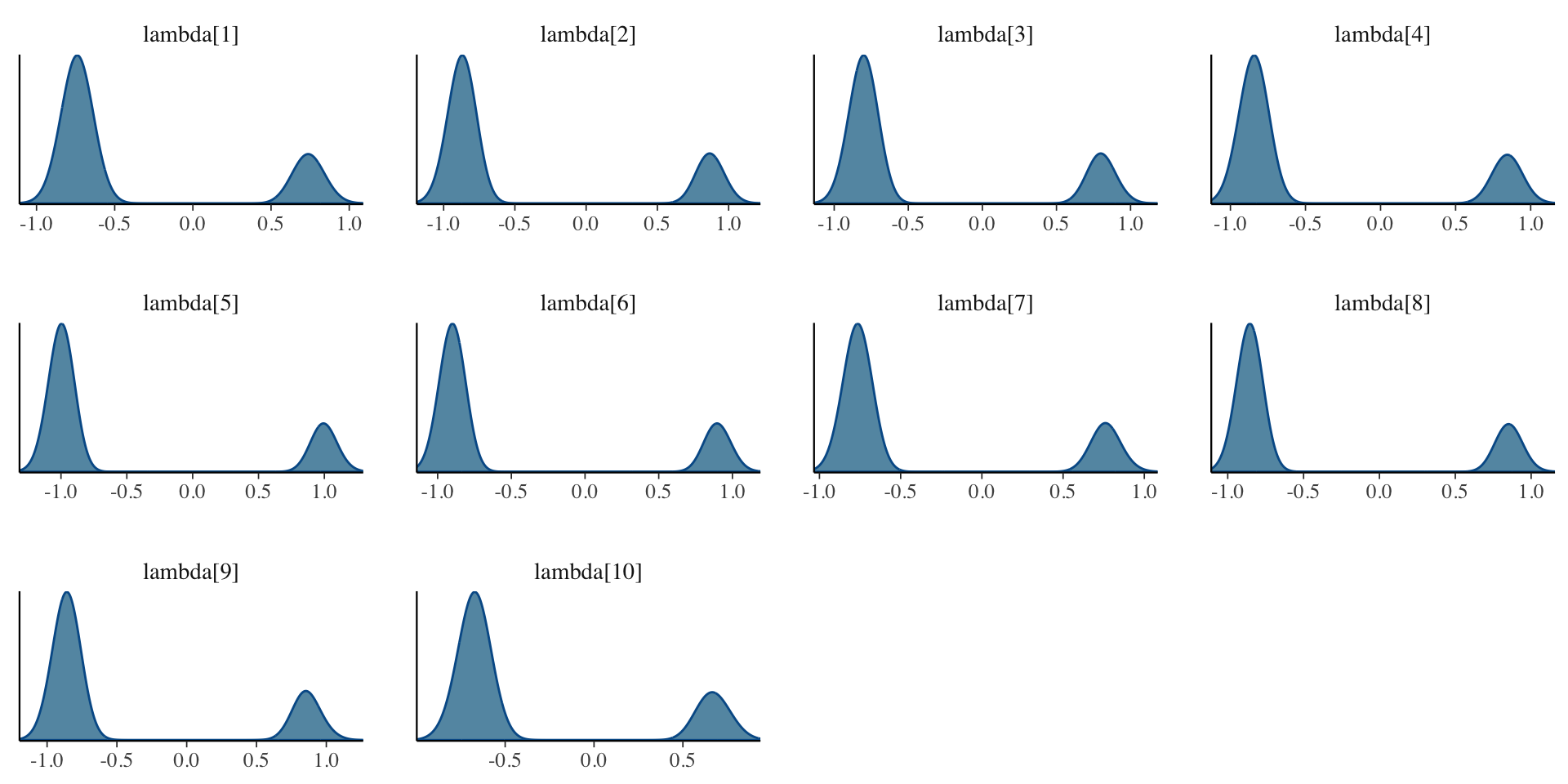
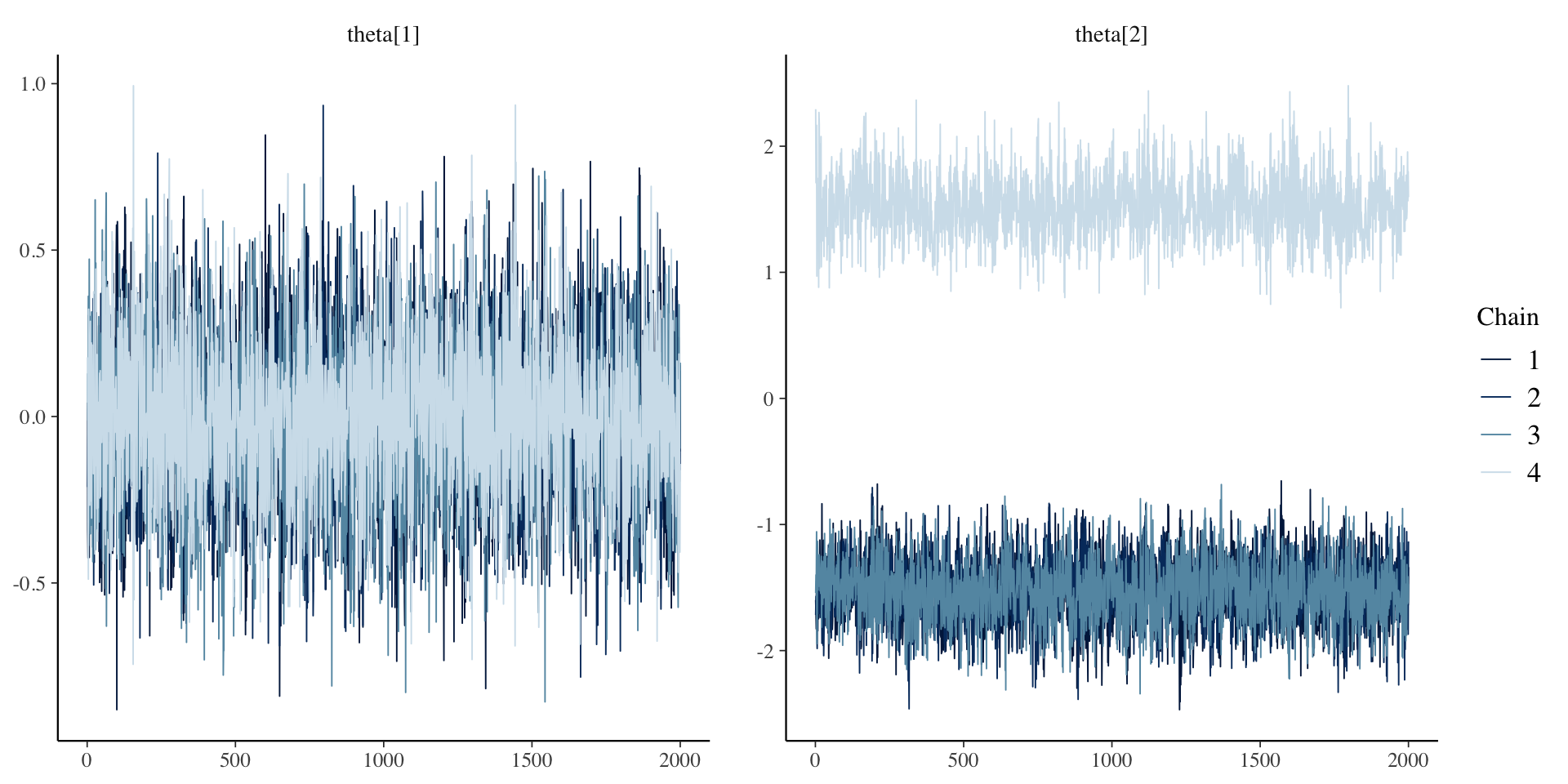
}Here, the parameterization of \(\lambda\) (factor loadings/discrimination parameters) can lead to problems in estimation
- The issue: \(\lambda_i \theta_p = (-\lambda_i)(-\theta_p)\)
- Depending on the random starting values of each of these parameters (per chain), a given chain may converge to a different region
- To demonstrate (later), we will start with a different random number seed
- Currently using 09102022: works fine
- Change to 25102022: big problems
New Samples Syntax
Trying the same model with a different random number seed:
Convergence: FAIL
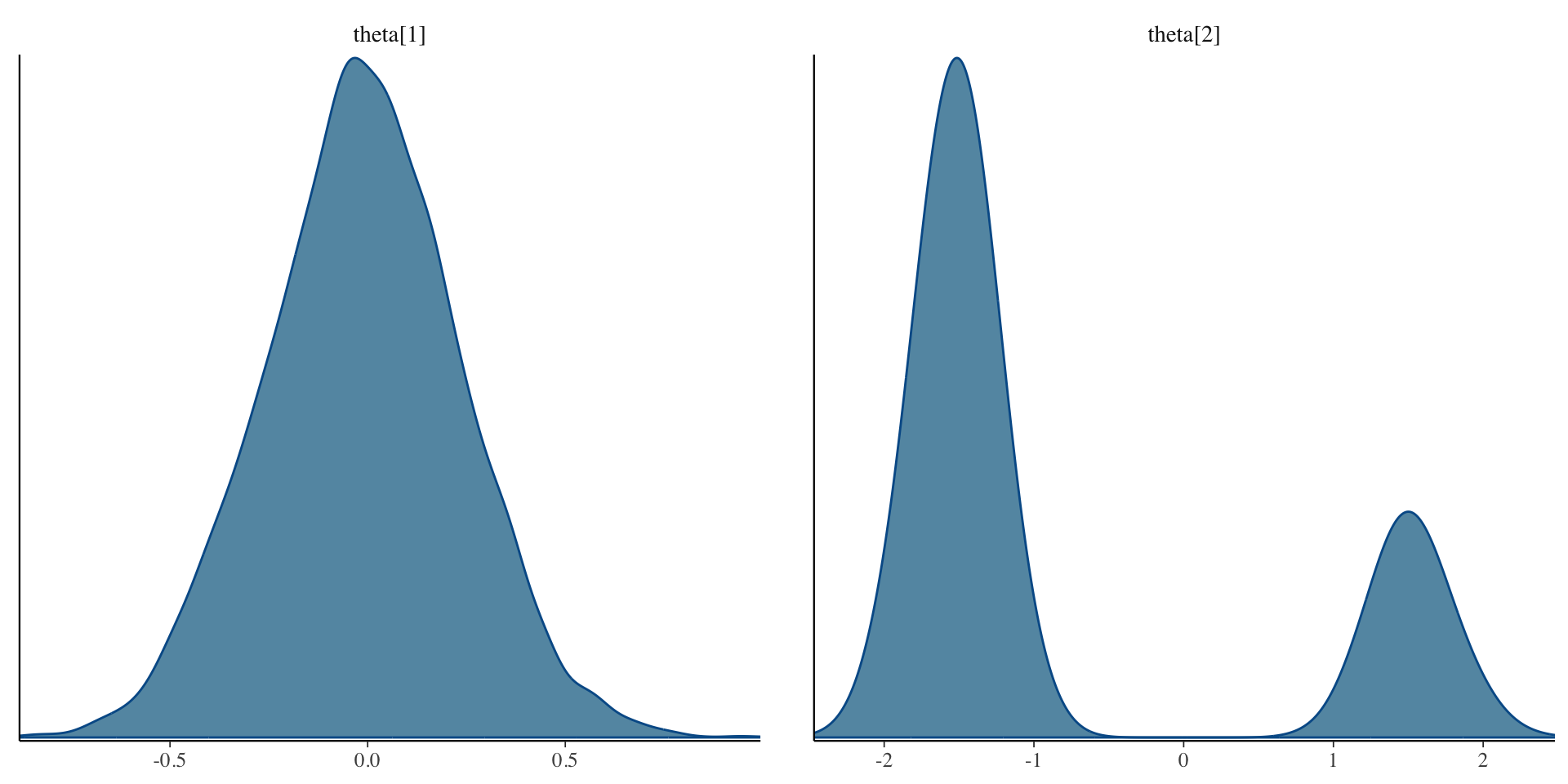
[1] 1.532298Why Convergence Failed
The issue: \(\lambda_i \theta_p = (-\lambda_i)(-\theta_p)\)
# A tibble: 30 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu[1] 2.37 2.37 0.0878 0.0887 2.23 2.51 1.00 1704. 3765.
2 mu[2] 1.96 1.96 0.0847 0.0833 1.82 2.10 1.00 1191. 2744.
3 mu[3] 1.88 1.88 0.0838 0.0844 1.74 2.02 1.00 1294. 3114.
4 mu[4] 2.01 2.01 0.0848 0.0835 1.87 2.15 1.00 1215. 3021.
5 mu[5] 1.99 1.99 0.0847 0.0843 1.85 2.13 1.00 911. 2148.
6 mu[6] 1.90 1.90 0.0765 0.0754 1.77 2.02 1.00 938. 2099.
7 mu[7] 1.73 1.73 0.0761 0.0755 1.60 1.85 1.00 1222. 2651.
8 mu[8] 1.85 1.84 0.0730 0.0729 1.72 1.96 1.00 927. 2010.
9 mu[9] 1.81 1.81 0.0870 0.0882 1.67 1.95 1.00 1268. 2962.
10 mu[10] 1.52 1.52 0.0804 0.0818 1.39 1.65 1.00 1679. 3728.
11 lambda[1] -0.371 -0.705 0.647 0.127 -0.867 0.808 1.53 7.12 27.0
12 lambda[2] -0.437 -0.837 0.760 0.120 -0.994 0.934 1.53 7.19 30.2
13 lambda[3] -0.403 -0.770 0.701 0.121 -0.923 0.865 1.53 7.18 30.1
14 lambda[4] -0.423 -0.810 0.736 0.121 -0.964 0.910 1.53 7.20 27.6
15 lambda[5] -0.500 -0.966 0.868 0.109 -1.11 1.06 1.53 7.29 29.0
16 lambda[6] -0.451 -0.872 0.783 0.101 -1.00 0.959 1.53 7.24 29.1
17 lambda[7] -0.384 -0.736 0.667 0.108 -0.873 0.824 1.53 7.21 28.5
18 lambda[8] -0.429 -0.829 0.743 0.0931 -0.951 0.908 1.53 7.24 30.0
19 lambda[9] -0.431 -0.827 0.751 0.124 -0.984 0.929 1.53 7.18 30.4
20 lambda[10] -0.338 -0.641 0.588 0.117 -0.790 0.738 1.53 7.15 29.6
21 psi[1] 0.892 0.890 0.0500 0.0491 0.813 0.977 1.00 15991. 6212.
22 psi[2] 0.734 0.733 0.0426 0.0417 0.667 0.807 1.00 14525. 6694.
23 psi[3] 0.782 0.779 0.0448 0.0445 0.710 0.857 1.00 15772. 6470.
24 psi[4] 0.757 0.755 0.0447 0.0436 0.688 0.835 1.00 14214. 6286.
25 psi[5] 0.545 0.543 0.0375 0.0383 0.486 0.609 1.00 9175. 7161.
26 psi[6] 0.505 0.504 0.0339 0.0338 0.452 0.563 1.00 9744. 6970.
27 psi[7] 0.686 0.684 0.0408 0.0413 0.622 0.755 1.00 13685. 6203.
28 psi[8] 0.480 0.478 0.0315 0.0309 0.429 0.533 1.00 9735. 6357.
29 psi[9] 0.782 0.780 0.0459 0.0453 0.711 0.859 1.00 13962. 6709.
30 psi[10] 0.840 0.838 0.0472 0.0467 0.766 0.922 1.00 15695. 6457. Posterior Trace Plots of \(\lambda\)
Posterior Density Plots of \(\lambda\)
Examining Latent Variables
# A tibble: 177 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 theta[1] -0.0112 -0.0124 0.246 0.241 -0.420 0.388 1.00 5428. 4806.
2 theta[2] -0.762 -1.41 1.35 0.402 -1.92 1.74 1.53 7.12 27.3
3 theta[3] -0.850 -1.58 1.49 0.420 -2.11 1.92 1.53 7.12 28.2
4 theta[4] 0.461 0.827 0.847 0.387 -1.15 1.29 1.53 7.10 28.2
5 theta[5] -0.0161 -0.0148 0.249 0.252 -0.424 0.384 1.01 884. 4643.
6 theta[6] 0.486 0.871 0.892 0.395 -1.21 1.36 1.53 7.12 26.9
7 theta[7] 0.170 0.238 0.390 0.368 -0.562 0.721 1.45 7.77 26.8
8 theta[8] 0.0254 0.0241 0.247 0.248 -0.380 0.433 1.03 111. 3910.
9 theta[9] 0.389 0.674 0.730 0.396 -1.00 1.15 1.53 7.11 26.5
10 theta[10] -0.0232 -0.0241 0.247 0.249 -0.431 0.381 1.01 924. 4544.
# ℹ 167 more rowsPosterior Trace Plots of \(\theta\)
Posterior Density Plots of \(\theta\)
Fixing Convergence
Stan allows starting values to be set via cmdstanr
- Documentation is very lacking, but with some trial and a lot of error, I will show you how
Alternatively:
- Restrict \(\lambda\) to be positive
- Truncates prior distribution with MVN
- Can also choose prior that has strictly positive range (like log-normal)
- Note: The restriction on the space of \(\lambda\) will not permit truely negative values
- Not ideal as negative \(\lambda\) values are informative as a problem with data
parameters {
vector[nObs] theta; // the latent variables (one for each person)
vector[nItems] mu; // the item intercepts (one for each item)
vector<lower=0>[nItems] lambda; // the factor loadings/item discriminations (one for each item)
vector<lower=0>[nItems] psi; // the unique standard deviations (one for each item)
}Setting Starting Values in Stan
Starting values (initial values) are the first values used when an MCMC chain starts
- In Stan, by default, parameters are randomly started between -2 and 2
- Bounded parameters are transformed so they are unbounded in the algorithm
- What we need:
- Randomly start all \(\lambda\) parameters so that they converge to the \(\lambda_i\theta_p\) mode
- As opposed to the \((-\lambda_i)(-\theta_p)\) mode
- Randomly start all \(\lambda\) parameters so that they converge to the \(\lambda_i\theta_p\) mode
cmdstanr Syntax for Initial Values
Add the init option to the $sample() function of the cmdstanr object:
The init option can be specified as a function, here, randomly starting each \(\lambda\) following a normal distribution
Initialization Process
See the lecture R syntax for information on how to confirm starting values are set
Final Results: Parameters
[1] 1.00472# A tibble: 30 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu[1] 2.37 2.36 0.0878 0.0863 2.22 2.51 1.00 1086. 2547.
2 mu[2] 1.95 1.95 0.0857 0.0845 1.81 2.10 1.00 725. 1588.
3 mu[3] 1.87 1.87 0.0862 0.0870 1.73 2.02 1.00 854. 1829.
4 mu[4] 2.01 2.01 0.0868 0.0866 1.87 2.16 1.00 777. 1397.
5 mu[5] 1.98 1.98 0.0874 0.0857 1.84 2.13 1.00 585. 980.
6 mu[6] 1.89 1.89 0.0793 0.0788 1.76 2.02 1.00 609. 1139.
7 mu[7] 1.72 1.72 0.0782 0.0761 1.59 1.85 1.00 770. 1520.
8 mu[8] 1.84 1.84 0.0750 0.0755 1.72 1.96 1.00 580. 1062.
9 mu[9] 1.81 1.81 0.0884 0.0874 1.66 1.95 1.00 796. 1728.
10 mu[10] 1.52 1.52 0.0825 0.0824 1.38 1.66 1.00 1122. 2205.
11 lambda[1] 0.737 0.734 0.0827 0.0811 0.605 0.876 1.00 3302. 4406.
12 lambda[2] 0.870 0.866 0.0767 0.0776 0.750 1.00 1.00 2181. 3811.
13 lambda[3] 0.802 0.799 0.0768 0.0775 0.679 0.930 1.00 2580. 4391.
14 lambda[4] 0.843 0.841 0.0767 0.0758 0.720 0.971 1.00 2282. 4093.
15 lambda[5] 0.997 0.994 0.0691 0.0696 0.887 1.12 1.00 1446. 2984.
16 lambda[6] 0.899 0.896 0.0636 0.0644 0.800 1.01 1.00 1464. 3098.
17 lambda[7] 0.765 0.763 0.0695 0.0680 0.654 0.883 1.00 2313. 3779.
18 lambda[8] 0.853 0.851 0.0609 0.0616 0.757 0.955 1.00 1547. 3327.
19 lambda[9] 0.861 0.858 0.0796 0.0777 0.734 0.995 1.00 2331. 4095.
20 lambda[10] 0.672 0.670 0.0771 0.0763 0.549 0.804 1.00 3427. 5018.
21 psi[1] 0.892 0.890 0.0503 0.0502 0.812 0.980 1.00 13357. 5746.
22 psi[2] 0.735 0.733 0.0437 0.0434 0.666 0.811 1.00 11126. 6092.
23 psi[3] 0.781 0.780 0.0452 0.0451 0.710 0.859 1.00 13015. 6448.
24 psi[4] 0.758 0.756 0.0441 0.0439 0.689 0.833 1.00 12527. 6555.
25 psi[5] 0.545 0.544 0.0368 0.0373 0.487 0.607 1.00 8108. 6781.
26 psi[6] 0.505 0.504 0.0341 0.0342 0.451 0.562 1.00 8063. 6345.
27 psi[7] 0.686 0.684 0.0396 0.0394 0.623 0.753 1.00 12978. 6088.
28 psi[8] 0.480 0.479 0.0314 0.0310 0.430 0.533 1.00 8821. 6431.
29 psi[9] 0.782 0.780 0.0462 0.0455 0.711 0.862 1.00 10379. 6070.
30 psi[10] 0.840 0.838 0.0467 0.0457 0.767 0.920 1.00 13767. 5702.Comparing Results
Plot of all parameters across both algorithm runs:
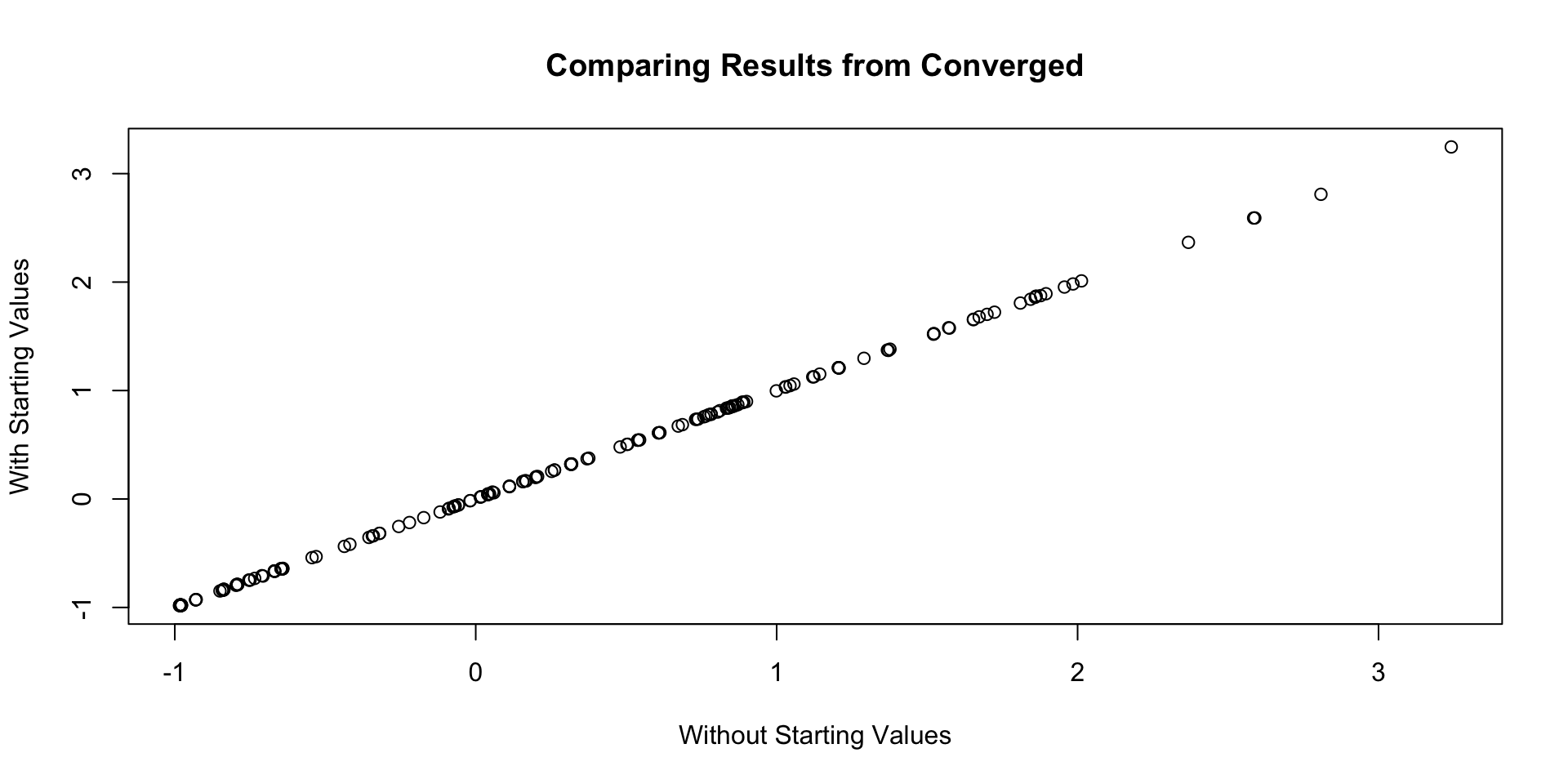
Correlation of all parameters across both algorithm runs:
[1] 0.9999964Wrapping Up
Wrapping Up
Today, we showed how to model observed data using a normal distribution
- Assumptions of Confirmatory Factor Analysis
- Not appropriate for our data
- May not be appropriate for many data sets
- We will have to keep our loading/discrimination parameters positive to ensure each chain converges to the same posterior mode
- This will continue through the next types of data
- Next up, categorical distributions for observed data
- More appropriate for these data as they are discrete categorical responses