model {
lambda ~ multi_normal(meanLambda, covLambda); // Prior for item discrimination/factor loadings
mu ~ multi_normal(meanMu, covMu); // Prior for item intercepts
theta ~ normal(0, 1); // Prior for latent variable (with mean/sd specified)
for (item in 1:nItems){
Y[item] ~ binomial(maxItem[item], inv_logit(mu[item] + lambda[item]*theta));
}
}Generalized Measurement Models: Modeling Observed Polytomous Data
Lecture 4d
Today’s Lecture Objectives
- Show how to estimate unidimensional latent variable models with polytomous data*
- Also known as Polytomous Item Repsonse Theory (IRT) or Item Factor Analysis (IFA) models
- Distributions appropriate for polytomous (discrete; data with lower/upper limits)
Example Data: Conspiracy Theories
Today’s example is from a bootstrap resample of 177 undergraduate students at a large state university in the Midwest. The survey was a measure of 10 questions about their beliefs in various conspiracy theories that were being passed around the internet in the early 2010s. Additionally, gender was included in the survey. All items responses were on a 5- point Likert scale with:
- Strongly Disagree
- Disagree
- Neither Agree or Disagree
- Agree
- Strongly Agree
Please note, the purpose of this survey was to study individual beliefs regarding conspiracies. The questions can provoke some strong emotions given the world we live in currently. All questions were approved by university IRB prior to their use.
Our purpose in using this instrument is to provide a context that we all may find relevant as many of these conspiracy theories are still prevalent today.
Conspiracy Theory Questions 1-5
Questions:
- The U.S. invasion of Iraq was not part of a campaign to fight terrorism, but was driven by oil companies and Jews in the U.S. and Israel.
- Certain U.S. government officials planned the attacks of September 11, 2001 because they wanted the United States to go to war in the Middle East.
- President Barack Obama was not really born in the United States and does not have an authentic Hawaiian birth certificate.
- The current financial crisis was secretly orchestrated by a small group of Wall Street bankers to extend the power of the Federal Reserve and further their control of the world’s economy.
- Vapor trails left by aircraft are actually chemical agents deliberately sprayed in a clandestine program directed by government officials.
Conspiracy Theory Questions 6-10
Questions:
- Billionaire George Soros is behind a hidden plot to destabilize the American government, take control of the media, and put the world under his control.
- The U.S. government is mandating the switch to compact fluorescent light bulbs because such lights make people more obedient and easier to control.
- Government officials are covertly Building a 12-lane "NAFTA superhighway" that runs from Mexico to Canada through America’s heartland.
- Government officials purposely developed and spread drugs like crack-cocaine and diseases like AIDS in order to destroy the African American community.
- God sent Hurricane Katrina to punish America for its sins.
From Previous Lectures: CFA (Normal Outcomes)
For comparisons today, we will be using the model where we assumed each outcome was (conditionally) normally distributed:
For an item \(i\) the model is:
\[ \begin{array}{cc} Y_{pi} = \mu_i + \lambda_i \theta_p + e_{p,i}; & e_{p,i} \sim N\left(0, \psi_i^2 \right) \\ \end{array} \]
Recall that this assumption wasn’t a good one as the type of data (discrete, bounded, some multimodality) did not match the normal distribution assumption
Plotting CFA (Normal Outcome) Results
Polytomous Data Distributions
Polytomous Data Characteristics
As we have done with each observed variable, we must decide which distribution to use
- To do this, we need to map the characteristics of our data on to distributions that share those characteristics
Our observed data:
- Discrete responses
- Small set of known categories: \({1, 2, 3, 4, 5}\)
- Some observed item responses may be multimodal
Choice of distribution must match
- Be capable of modeling a small set of known categories
- Discrete distribution
- Limited number of categories (with fixed upper bound)
- Possible multimodality
Discrete Data Distributions
Stan has a list of distributions for bounded discrete data: https://mc-stan.org/docs/functions-reference/bounded-discrete-distributions.html
- Binomial distribution
- Pro: Easy to use/code
- Con: Unimodal distribution
- Beta-binomial distribution
- Not often used in psychometrics (but could be)
- Generalizes binomial distribution to have different probability for each trial
- Hypergeometric distribution
- Not often used in psychometrics
- Categorical distribution (sometimes called multinomial)
- Most frequently used
- Base distribution for graded response, partial credit, and nominal response models
- Discrete range distribution (sometimes called uniform)
- Not useful–doesn’t have much information about latent variables
Binomial Distribution Models
Binomial Distribution Models
The binomial distribution is one of the easiest to use for polytomous items
- However, it assumes the distribution of responses are unimodal
Binomial probability mass function (i.e., pdf):
\[P(Y = y) = {n \choose y} p^k \left(1-p \right)^{(n-k)} \]
Parameters:
- \(n\) – “number of trials” (range: \(n \in \{0, 1, \ldots\}\))
- \(y\) – “number of successes” out of \(n\) “trials” (range: \(y \in \{0, 1, \ldots, n\}\))
- \(p\) – probability of “success” (range: \([0, 1]\))
Mean: \(np\)
Variance: \(np(1-p\))
Adapting the Binomial for Item Response Models
Although it doesn’t seem like our items fit with a binomial, we can actually use this distribution
- Item response: number of successes \(y_i\)
- Needed: recode data so that lowest category is \(0\) (subtract one from each item)
- Highest (recoded) item response: number of trials \(n\)
- For all our items, once recoded, \(n_i=4\) (\(\forall i\))
- Then, use a link function to model each item’s \(p_i\) as a function of the latent trait:
\[p_i = \frac{\exp\left(\mu_i + \lambda_i \theta_p)\right)}{1+\exp\left(\mu_i + \lambda_i \theta_p)\right)}\]
Note:
- Shown with a logit link function (but could be any link)
- Shown in slope/intercept form (but could be discrimination/difficulty for unidimensional items)
- Could also include asymptote parameters (\(c_i\) or \(d_i\))
Binomial Item Repsonse Model
The item response model, put into the PDF of the binomial is then:
\[P(Y_{pi} \mid \theta_p) = {n_i \choose Y_{pi}} \left(\frac{\exp\left(\mu_i + \lambda_i \theta_p)\right)}{1+\exp\left(\mu_i + \lambda_i \theta_p)\right)}\right)^{Y_{pi}} \left(1-\left(\frac{\exp\left(\mu_i + \lambda_i \theta_p)\right)}{1+\exp\left(\mu_i + \lambda_i \theta_p)\right)}\right) \right)^{(n_i-Y_{pi})} \]
Further, we can use the same priors as before on each of our item parameters
- \(\mu_i\): Normal prior \(N(0, 1000)\)
- \(\lambda_i\) Normal prior \(N(0, 1000)\)
Likewise, we can identify the scale of the latent variable as before, too:
- \(\theta_p \sim N(0,1)\)
Estimating the Binomial Model in Stan
Here, the binomial function has two arguments:
- The first (
maxItem[item]) is the number of “trials” \(n_i\) (here, our maximum score minus one) - The second
inv_logit(mu[item] + lambda[item]*theta)is the probability from our model (\(p_i\))
The data Y[item] must be:
- Type: integer
- Range: 0 through
maxItem[item]
Binomial Model Parameters Block
No changes from any of our previous slope/intercept models
Binomial Model Data Block
data {
int<lower=0> nObs; // number of observations
int<lower=0> nItems; // number of items
array[nItems] int<lower=0> maxItem;
array[nItems, nObs] int<lower=0> Y; // item responses in an array
vector[nItems] meanMu; // prior mean vector for intercept parameters
matrix[nItems, nItems] covMu; // prior covariance matrix for intercept parameters
vector[nItems] meanLambda; // prior mean vector for discrimination parameters
matrix[nItems, nItems] covLambda; // prior covariance matrix for discrimination parameters
}Note:
- Need to supply
maxItem(maximum score minus one for each item) - The data are the same (integer) as in the binary/dichotomous items syntax
Preparing Data for Stan
Binomial Model Stan Call
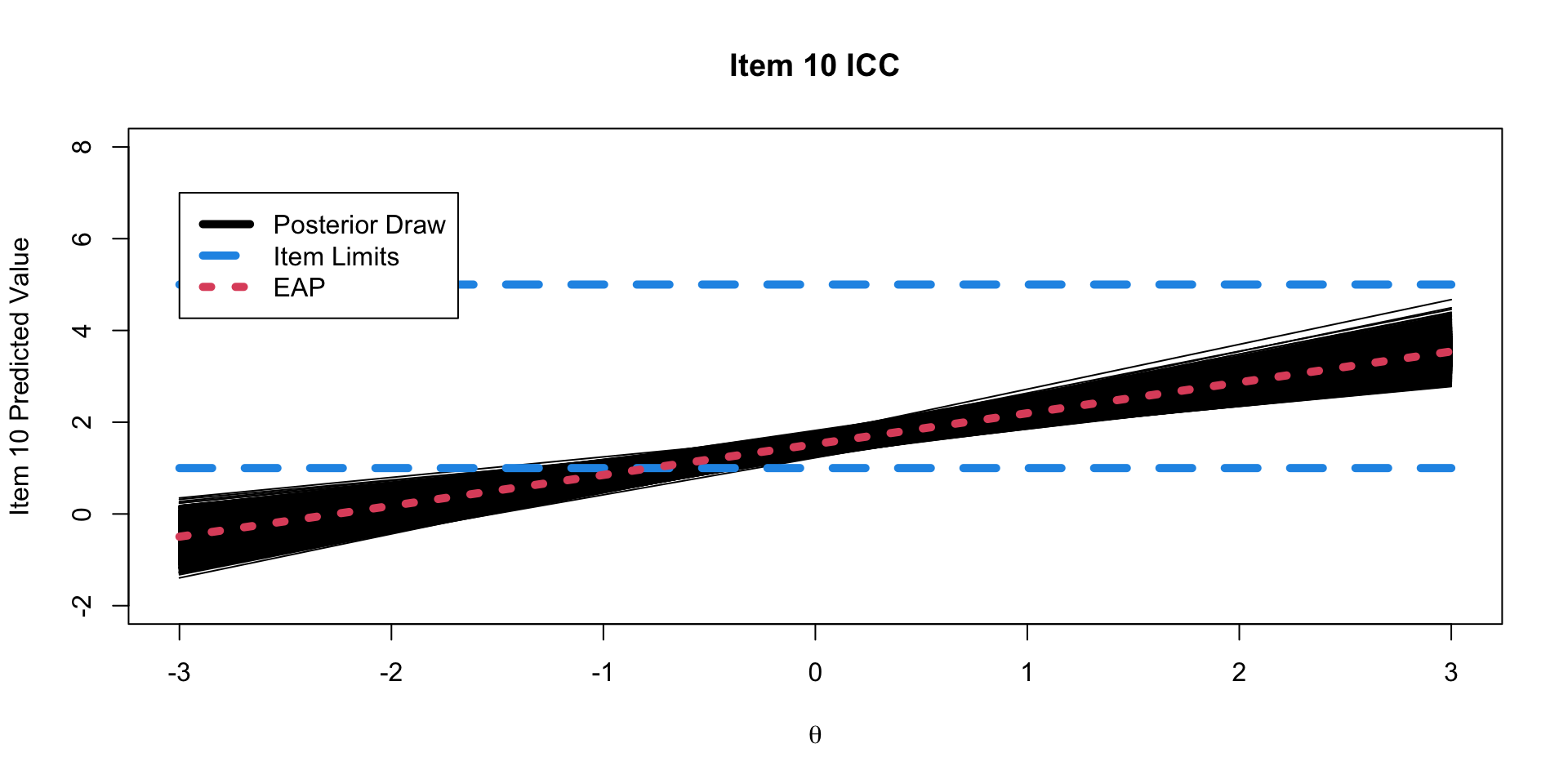
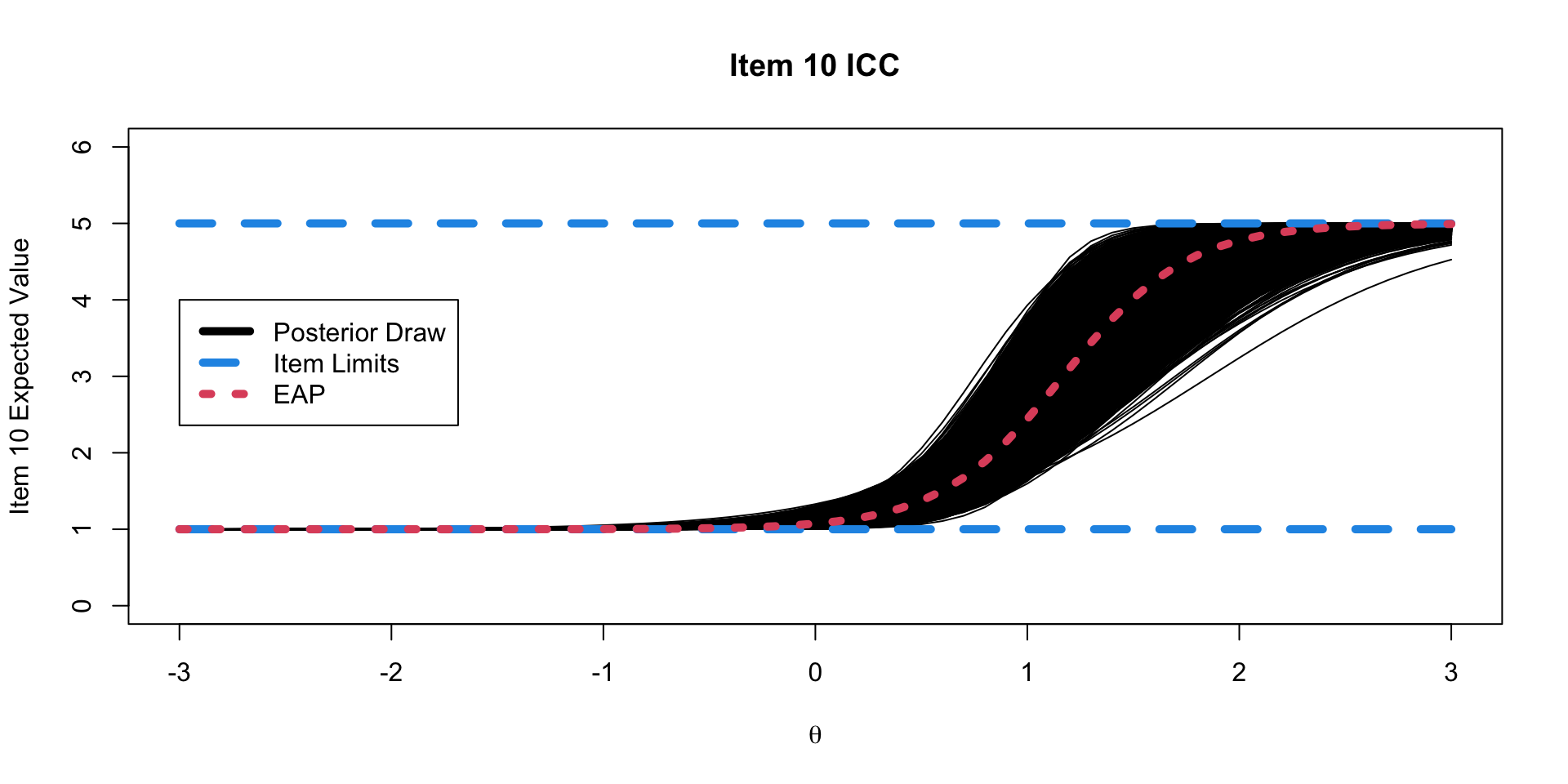
Binomial Model Results
[1] 1.000957# A tibble: 20 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu[1] -0.842 -0.839 0.127 0.124 -1.05 -0.636 1.00 2527. 5864.
2 mu[2] -1.84 -1.83 0.214 0.213 -2.20 -1.50 1.00 2413. 5088.
3 mu[3] -1.99 -1.98 0.223 0.220 -2.38 -1.64 1.00 2461. 6559.
4 mu[4] -1.73 -1.72 0.210 0.208 -2.08 -1.40 1.00 1896. 4566.
5 mu[5] -2.00 -1.99 0.252 0.253 -2.44 -1.61 1.00 2233. 5590.
6 mu[6] -2.10 -2.09 0.243 0.242 -2.52 -1.72 1.00 2176. 5810.
7 mu[7] -2.45 -2.43 0.265 0.262 -2.90 -2.03 1.00 2360. 6116.
8 mu[8] -2.16 -2.15 0.239 0.237 -2.57 -1.79 1.00 2162. 5316.
9 mu[9] -2.40 -2.39 0.278 0.275 -2.88 -1.97 1.00 2506. 6622.
10 mu[10] -3.98 -3.94 0.519 0.502 -4.89 -3.19 1.00 2823. 7291.
11 lambda[1] 1.11 1.10 0.143 0.142 0.881 1.35 1.00 5976. 9415.
12 lambda[2] 1.90 1.89 0.244 0.238 1.52 2.33 1.00 5167. 8013.
13 lambda[3] 1.92 1.90 0.256 0.253 1.52 2.36 1.00 4960. 7639.
14 lambda[4] 1.89 1.88 0.239 0.234 1.52 2.31 1.00 3959. 5469.
15 lambda[5] 2.28 2.26 0.284 0.282 1.84 2.77 1.00 4135. 5926.
16 lambda[6] 2.15 2.13 0.275 0.271 1.73 2.63 1.00 4391. 7256.
17 lambda[7] 2.13 2.11 0.295 0.288 1.68 2.65 1.00 4773. 6502.
18 lambda[8] 2.08 2.07 0.268 0.268 1.66 2.54 1.00 3914. 5351.
19 lambda[9] 2.34 2.33 0.316 0.311 1.86 2.89 1.00 4729. 7527.
20 lambda[10] 3.40 3.36 0.557 0.544 2.57 4.38 1.00 4772. 7579.Option Characteristic Curves
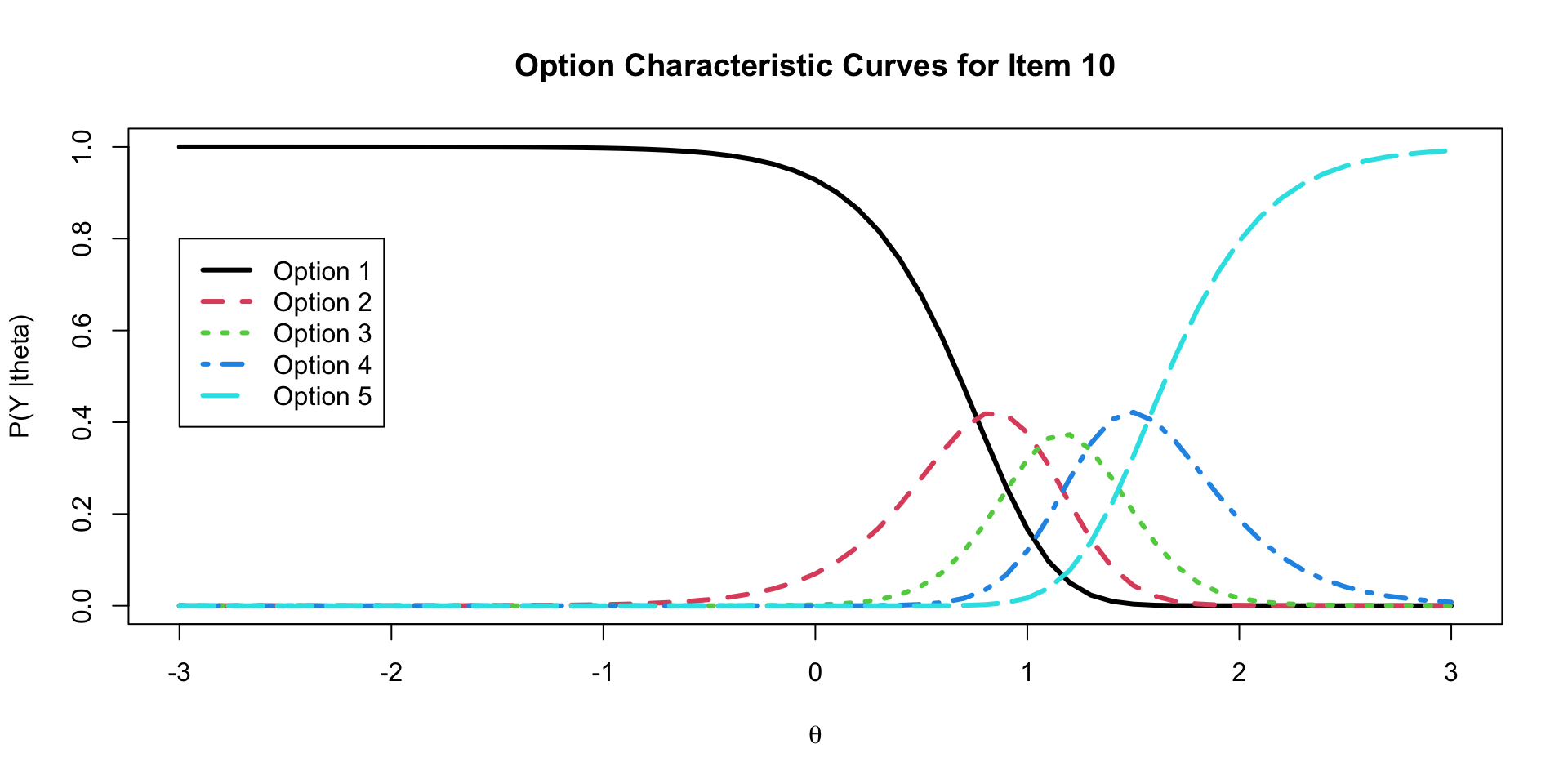
ICC Plots
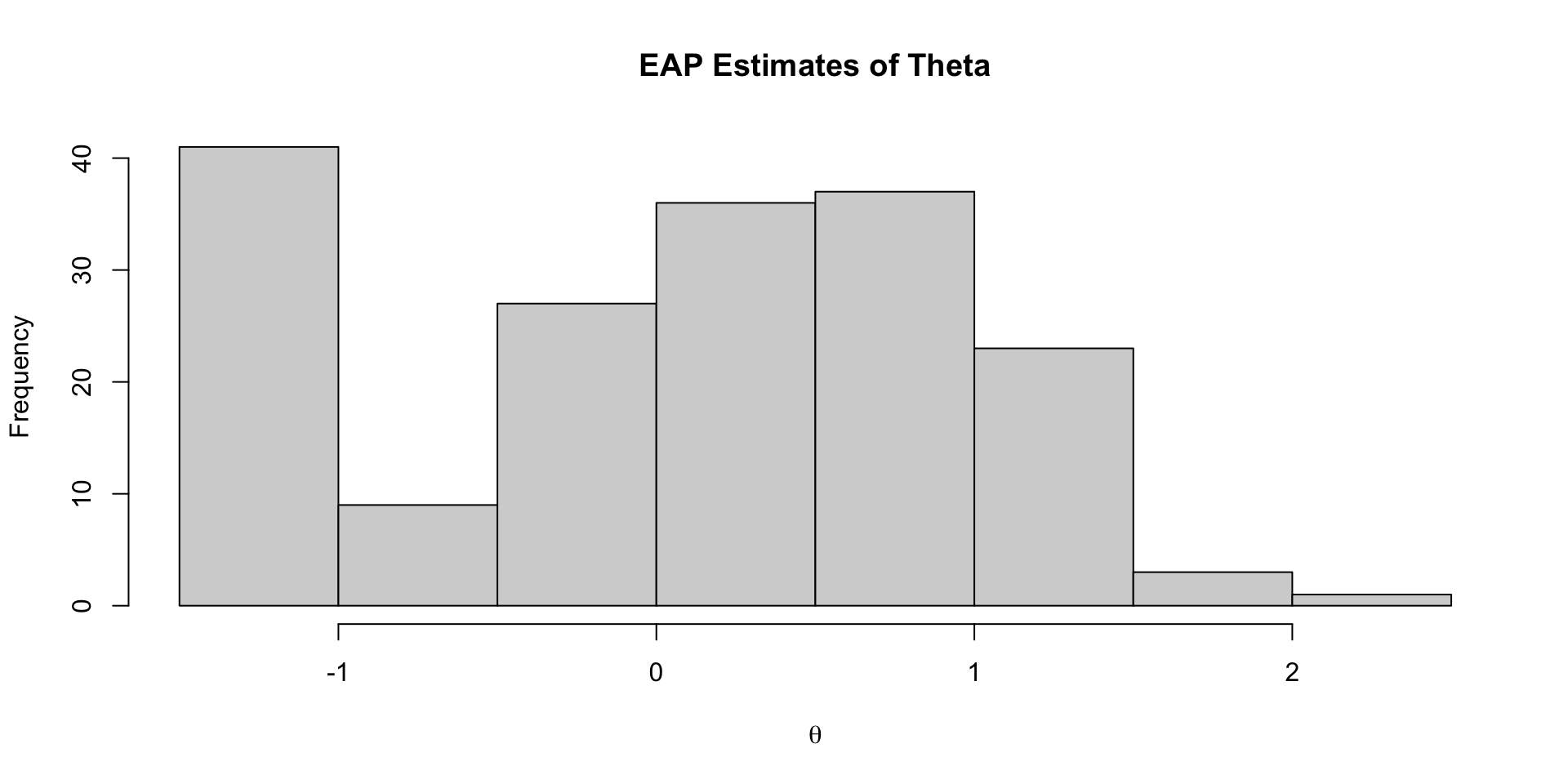
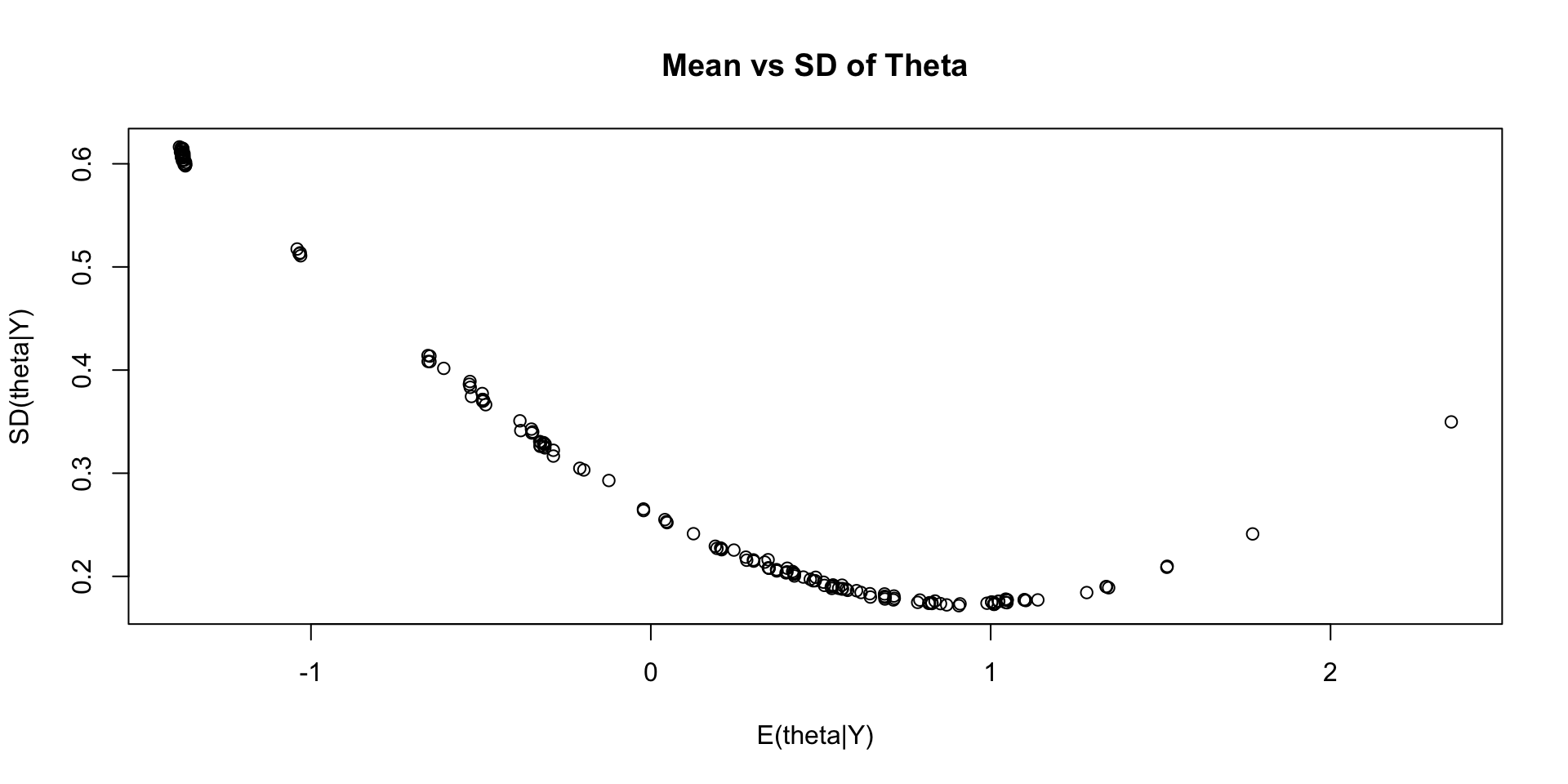
Investigating Latent Variable Estimates
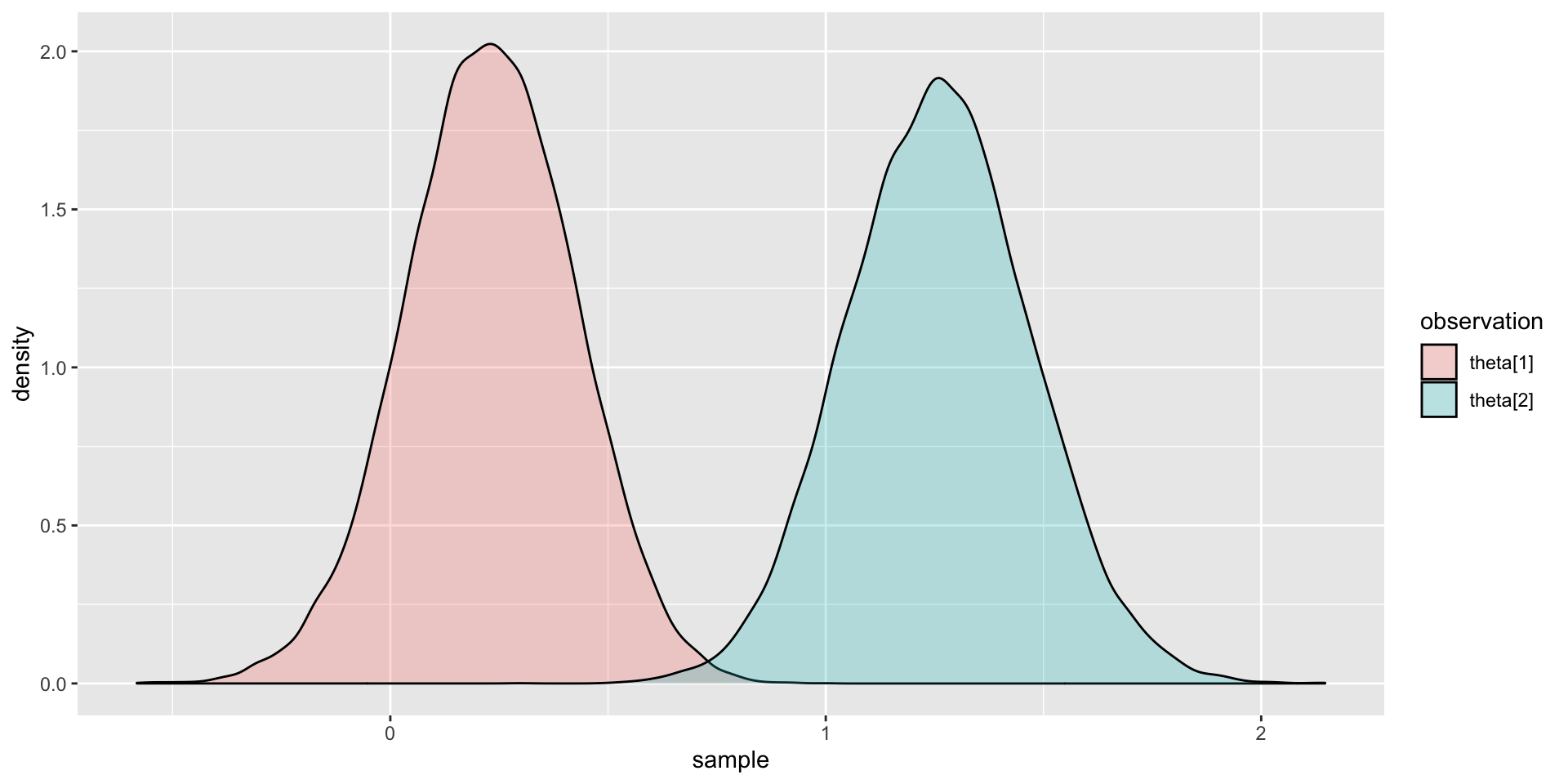
Comparing Two Latent Variable Posterior Distributions
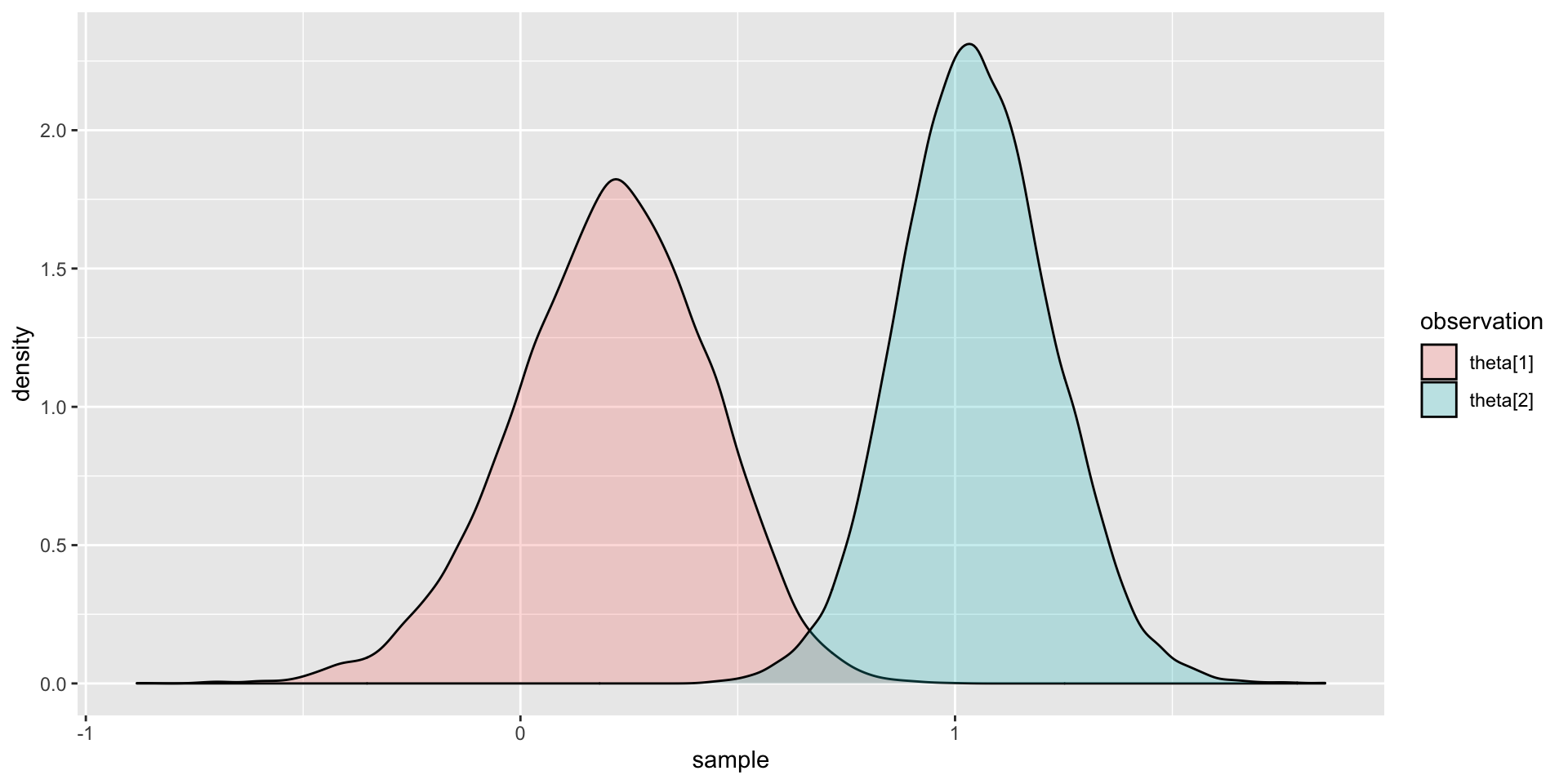
Comparing Latent Variable Posterior Mean and SDs
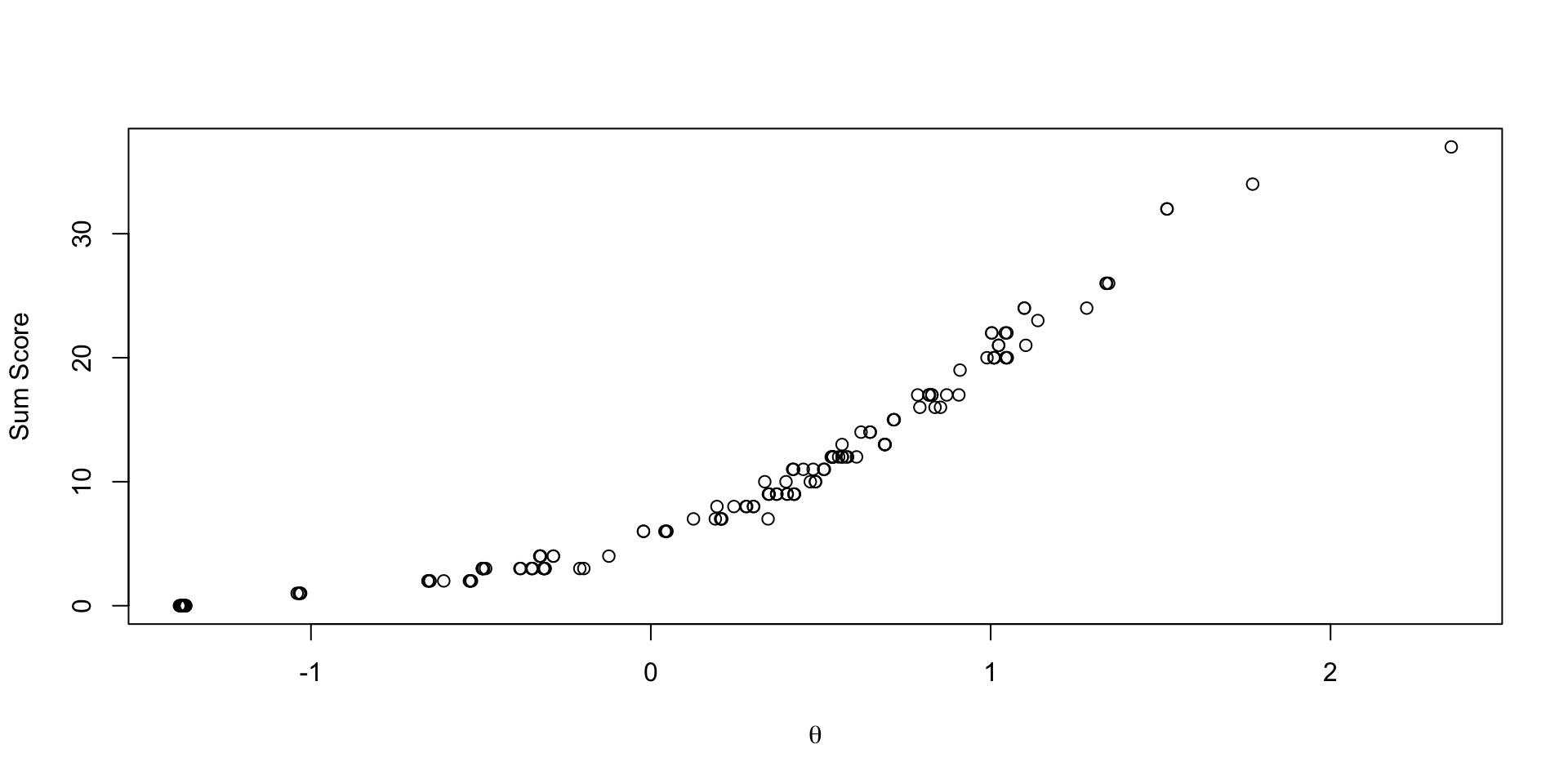
Comparing EAP Estimates with Sum Scores
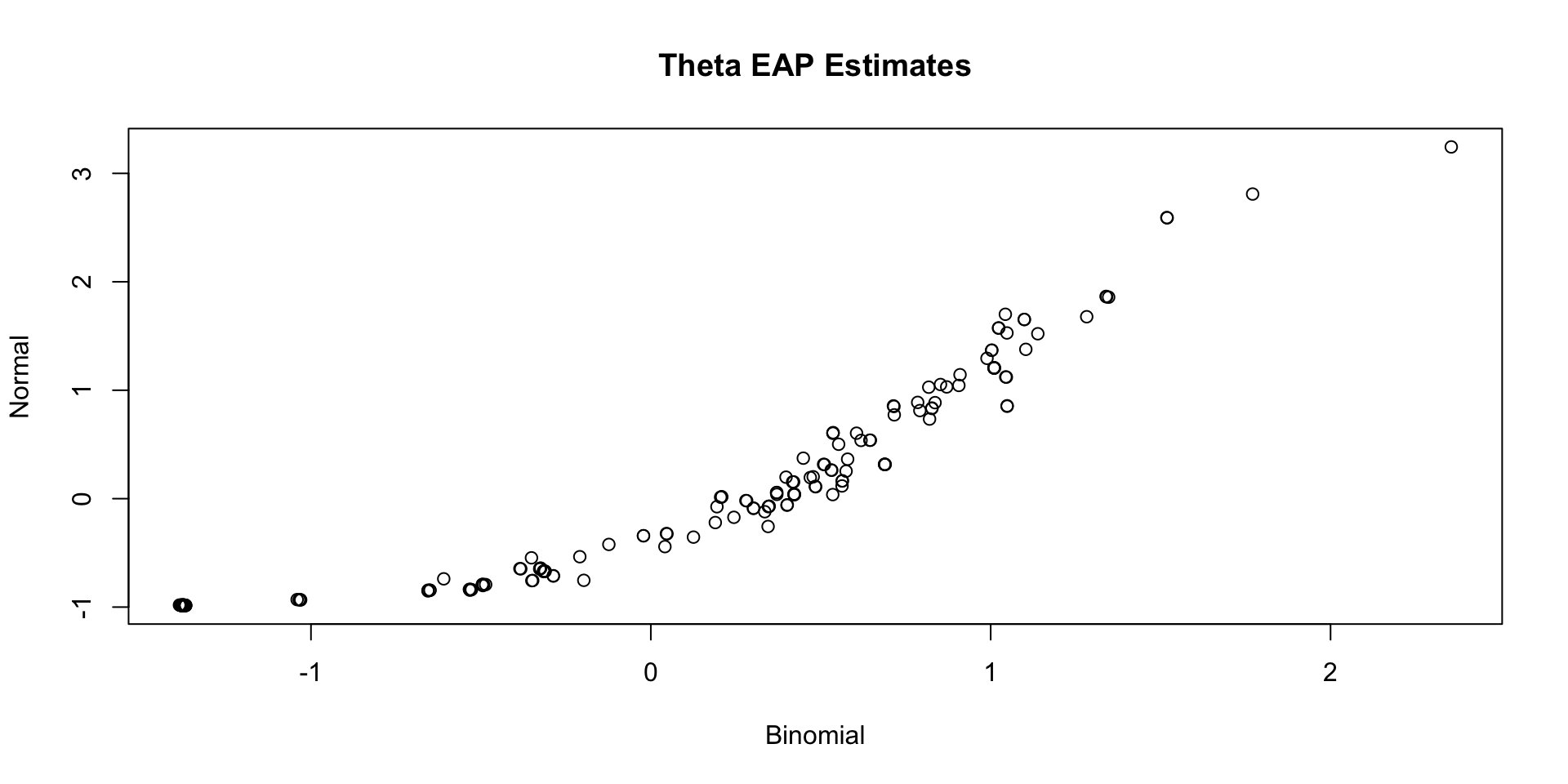
Comparing Thetas: Binomial vs Normal
Categorical/Multinomial Distribution Models
Categorical/Multinomial Distribution Models
Although the binomial distribution is easy, it may not fit our data well
- Instead, we can use the categorical (sometimes called multinomial) distribution, with pmf (pdf):
\[P(Y = y) = \frac{n!}{y_1! \cdots y_C!}p_1^{y_1}\cdots p_C^{y_C}\]
Here:
- \(n\): number of “trials”
- \(y_c\): number of events in each of \(c\) categories (\(c \in \{1, \ldots, C\}\); \(\sum_c y_c = n\))
- \(p_c\): probability of observing an event in category \(c\)
Adapting the Multinomial Distribution for Item Response Models
With some definitions, we can make a multinomial distribution into one we can use for polytomous item response models
- The number of “trials” is set to one for all items \(n_i=1\) (\(\forall i\))
- With \(n_i = 1\), this is called the categorical distribution
\[P(Y_{pi} \mid \theta_p) = p_{i1}^{I(y_{pi}=1)}\cdots p_{iC_i}^{I(y_{pi}=C_i)}\]
- The number of categories is equal to the number of options on an item (\(C_i\))
- The item response model is specified for the set of probabilities \(p_{ic}\), with \(\sum_c p_{ic}=1\)
- Then, use a link function to model each item’s set of \(p_{ic}\) as a function of the latent trait
Choices for Models for Probability of Each Category \(p_{ic}\)
The most-frequently used polytomous item response models all use the categorical distribution for observed data
- They differ in how the model function builds the conditional response probabilities
- Graded response models: set of ordered intercepts (or thresholds) and a single loading
- Called proportional odds models in categorical data analysis
- Partial credit models: set of unordered difficulty parameters and a single loading
- Nominal response models: set of unordered intercepts and set of loadings
- Called generalized logit models in categorical data analysis
- Graded response models: set of ordered intercepts (or thresholds) and a single loading
- Terminology note:
- Terms graded response and partial credit come from educational measurement
- Data need not be graded response/partial credit to you
- Terms graded response and partial credit come from educational measurement
Graded Response Model
The graded response model is an ordered logistic regression model where:
\[P\left(Y_{ic } \mid \theta \right) = \left\{ \begin{array}{lr} 1-P^*\left(Y_{i1} \mid \theta \right) & \text{if } c=1 \\ P^*\left(Y_{i{c-1}} \mid \theta \right) - P^*\left(Y_{i{c}} \mid \theta \right) & \text{if } 1<c<C_i \\ P^*\left(Y_{i{C_i -1} } \mid \theta \right) & \text{if } c=C_i \\ \end{array} \right.\]
Where:
\[P^*\left(Y_{i{c}} \mid \theta \right) = \frac{\exp(\mu_{ic}+\lambda_i\theta_p)}{1+\exp(\mu_{ic}+\lambda_i\theta_p)}\]
With:
- \(C_i-1\) Ordered intercepts: \(\mu_1 > \mu_2 > \ldots > \mu_{C_i-1}\)
Estimating the Graded Response Model in Stan
model {
lambda ~ multi_normal(meanLambda, covLambda); // Prior for item discrimination/factor loadings
theta ~ normal(0, 1); // Prior for latent variable (with mean/sd specified)
for (item in 1:nItems){
thr[item] ~ multi_normal(meanThr[item], covThr[item]); // Prior for item intercepts
Y[item] ~ ordered_logistic(lambda[item]*theta, thr[item]);
}
}Notes:
ordered_logisticis a built in Stan function that makes the model easy to implement- Instead of intercepts, however, it uses thresholds: ${ic} = -{ic} $
- First argument is the linear predictor (the non-intercept portion of the model)
- Second argument is the set of thresholds for the item
- The function expects the responses of \(Y\) to start at one and go to maxCategory (\(Y_{pi}\) {1, , C_i})
- No transformation needed to data (unless some categories have zero observations)
Graded Response Model parameters Block
Notes:
- Threshold parameters:
array[nItems] ordered[maxCategory-1] thr;Is an array (each item has maxCategory-1) parameters
Is of type
ordered: Automatically ensures order is maintained\[ \tau_{i1} < \tau_{i2} < \ldots < \tau_{iC-1}\]
Graded Response Model generated quantities Block
We use generated quantities to convert threshold parameters into intercepts
Graded Response Model data block
data {
int<lower=0> nObs; // number of observations
int<lower=0> nItems; // number of items
int<lower=0> maxCategory;
array[nItems, nObs] int<lower=1, upper=5> Y; // item responses in an array
array[nItems] vector[maxCategory-1] meanThr; // prior mean vector for intercept parameters
array[nItems] matrix[maxCategory-1, maxCategory-1] covThr; // prior covariance matrix for intercept parameters
vector[nItems] meanLambda; // prior mean vector for discrimination parameters
matrix[nItems, nItems] covLambda; // prior covariance matrix for discrimination parameters
}Notes:
- The input for the prior mean/covariance matrix for threshold parameters is now an array (one mean vector and covariance matrix per item)
Graded Response Model Data Preparation
To match the array for input for the threshold hyperparameter matrices, a little data manipulation is needed
# item threshold hyperparameters
thrMeanHyperParameter = 0
thrMeanVecHP = rep(thrMeanHyperParameter, maxCategory-1)
thrMeanMatrix = NULL
for (item in 1:nItems){
thrMeanMatrix = rbind(thrMeanMatrix, thrMeanVecHP)
}
thrVarianceHyperParameter = 1000
thrCovarianceMatrixHP = diag(x = thrVarianceHyperParameter, nrow = maxCategory-1)
thrCovArray = array(data = 0, dim = c(nItems, maxCategory-1, maxCategory-1))
for (item in 1:nItems){
thrCovArray[item, , ] = diag(x = thrVarianceHyperParameter, nrow = maxCategory-1)
}- The R array matches stan’s array type
Graded Response Model Stan Call
Note: Using positive starting values for the \(\lambda\) parameters
Graded Response Model Results
[1] 1.002496# item parameter results
print(modelOrderedLogit_samples$summary(variables = c("lambda", "mu")) ,n=Inf)# A tibble: 50 × 10
variable mean median sd mad q5 q95 rhat ess_bulk
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lambda[1] 2.14 2.13 0.289 0.285 1.69 2.63 1.00 5439.
2 lambda[2] 3.08 3.05 0.432 0.424 2.42 3.84 1.00 5761.
3 lambda[3] 2.60 2.57 0.389 0.380 2.00 3.27 1.00 5731.
4 lambda[4] 3.11 3.08 0.429 0.425 2.45 3.85 1.00 5565.
5 lambda[5] 5.02 4.95 0.768 0.744 3.88 6.37 1.00 4909.
6 lambda[6] 5.04 4.98 0.761 0.745 3.92 6.39 1.00 4960.
7 lambda[7] 3.25 3.22 0.500 0.485 2.49 4.12 1.00 5283.
8 lambda[8] 5.37 5.28 0.863 0.829 4.12 6.91 1.00 5165.
9 lambda[9] 3.15 3.12 0.484 0.476 2.42 4.00 1.00 5564.
10 lambda[10] 2.67 2.64 0.474 0.464 1.94 3.50 1.00 6777.
11 mu[1,1] 1.49 1.48 0.289 0.284 1.03 1.97 1.00 2640.
12 mu[2,1] 0.173 0.178 0.339 0.331 -0.384 0.721 1.00 1769.
13 mu[3,1] -0.456 -0.447 0.305 0.300 -0.976 0.0319 1.00 1986.
14 mu[4,1] 0.346 0.346 0.341 0.333 -0.222 0.900 1.00 1711.
15 mu[5,1] 0.321 0.326 0.507 0.501 -0.511 1.14 1.00 1429.
16 mu[6,1] -0.0440 -0.0295 0.509 0.493 -0.909 0.765 1.00 1451.
17 mu[7,1] -0.822 -0.804 0.374 0.366 -1.47 -0.243 1.00 1832.
18 mu[8,1] -0.395 -0.374 0.548 0.527 -1.33 0.465 1.00 1469.
19 mu[9,1] -0.746 -0.733 0.360 0.355 -1.36 -0.185 1.00 1812.
20 mu[10,1] -1.98 -1.95 0.399 0.390 -2.68 -1.37 1.00 2533.
21 mu[1,2] -0.659 -0.651 0.262 0.261 -1.10 -0.245 1.00 2192.
22 mu[2,2] -2.21 -2.20 0.400 0.394 -2.90 -1.60 1.00 2370.
23 mu[3,2] -1.68 -1.66 0.336 0.330 -2.26 -1.15 1.00 2279.
24 mu[4,2] -1.80 -1.79 0.372 0.364 -2.43 -1.21 1.00 1924.
25 mu[5,2] -3.19 -3.15 0.636 0.618 -4.29 -2.23 1.00 2196.
26 mu[6,2] -3.26 -3.21 0.634 0.612 -4.38 -2.29 1.00 1937.
27 mu[7,2] -2.74 -2.71 0.447 0.436 -3.52 -2.05 1.00 2520.
28 mu[8,2] -3.28 -3.22 0.664 0.638 -4.45 -2.28 1.00 1954.
29 mu[9,2] -2.67 -2.64 0.444 0.438 -3.44 -1.99 1.00 2580.
30 mu[10,2] -3.26 -3.23 0.468 0.458 -4.09 -2.54 1.00 3525.
31 mu[1,3] -2.51 -2.50 0.321 0.318 -3.06 -2.00 1.00 3070.
32 mu[2,3] -4.14 -4.12 0.505 0.492 -5.00 -3.35 1.00 3604.
33 mu[3,3] -4.38 -4.35 0.525 0.512 -5.27 -3.55 1.00 4790.
34 mu[4,3] -4.60 -4.57 0.545 0.535 -5.54 -3.75 1.00 3657.
35 mu[5,3] -6.04 -5.97 0.866 0.842 -7.56 -4.73 1.00 3457.
36 mu[6,3] -7.48 -7.40 1.03 1.02 -9.28 -5.93 1.00 4063.
37 mu[7,3] -5.13 -5.09 0.650 0.640 -6.25 -4.13 1.00 4328.
38 mu[8,3] -9.04 -8.92 1.33 1.28 -11.4 -7.06 1.00 4620.
39 mu[9,3] -4.00 -3.97 0.529 0.523 -4.93 -3.19 1.00 3598.
40 mu[10,3] -4.49 -4.45 0.569 0.561 -5.47 -3.61 1.00 4289.
41 mu[1,4] -4.52 -4.50 0.513 0.509 -5.41 -3.72 1.00 6625.
42 mu[2,4] -5.76 -5.73 0.684 0.677 -6.96 -4.71 1.00 5738.
43 mu[3,4] -5.54 -5.50 0.666 0.652 -6.71 -4.51 1.00 6847.
44 mu[4,4] -5.56 -5.53 0.640 0.629 -6.65 -4.54 1.00 4720.
45 mu[5,4] -8.63 -8.55 1.18 1.14 -10.7 -6.86 1.00 5331.
46 mu[6,4] -10.4 -10.3 1.46 1.42 -13.0 -8.24 1.00 6090.
47 mu[7,4] -6.88 -6.82 0.882 0.864 -8.42 -5.53 1.00 6505.
48 mu[8,4] -12.1 -11.9 1.93 1.86 -15.6 -9.30 1.00 7356.
49 mu[9,4] -5.80 -5.76 0.712 0.712 -7.03 -4.69 1.00 5623.
50 mu[10,4] -4.75 -4.71 0.597 0.588 -5.79 -3.83 1.00 4625.
# … with 1 more variable: ess_tail <dbl>Graded Response Model Option Characteristic Curves
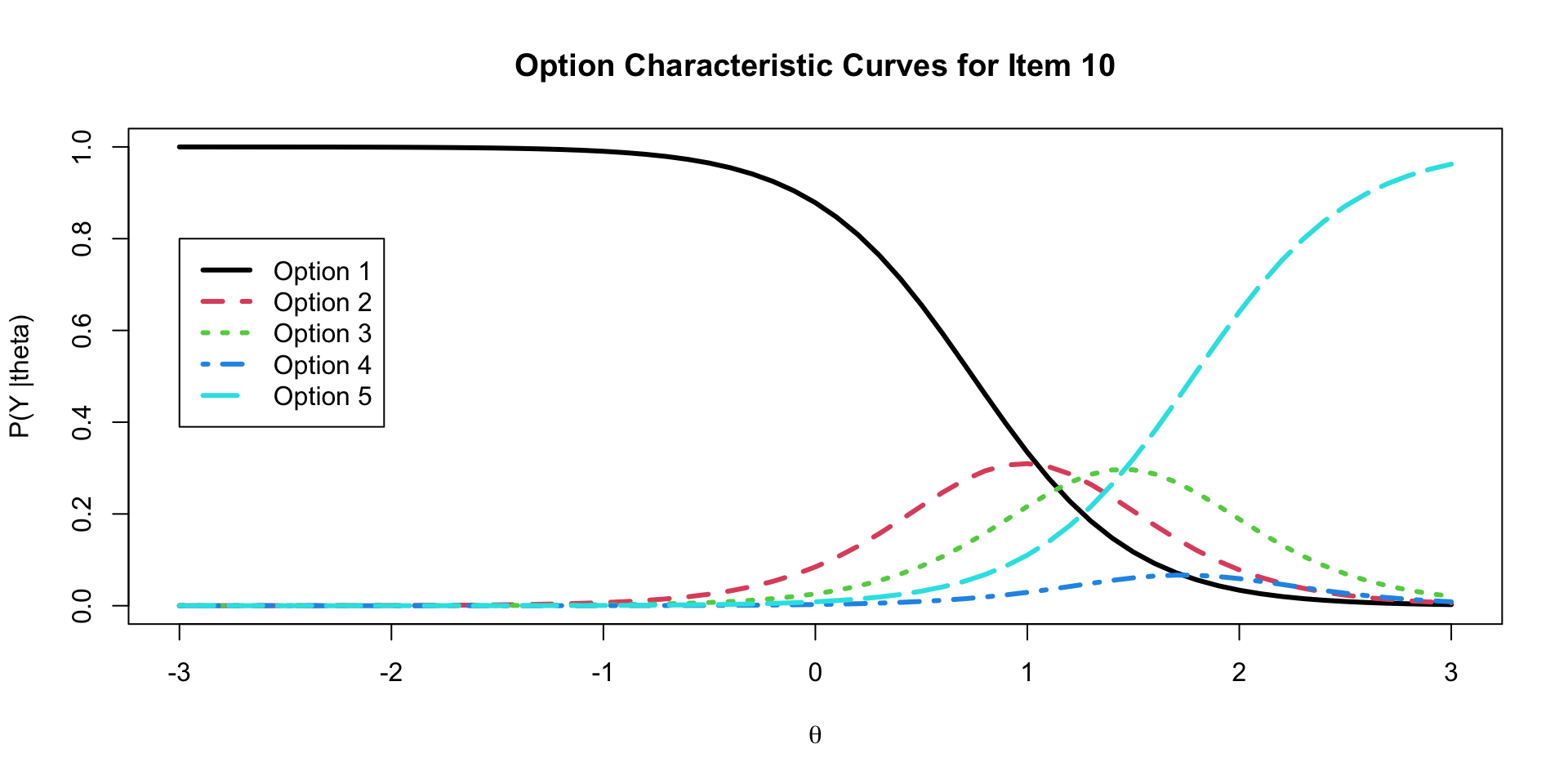
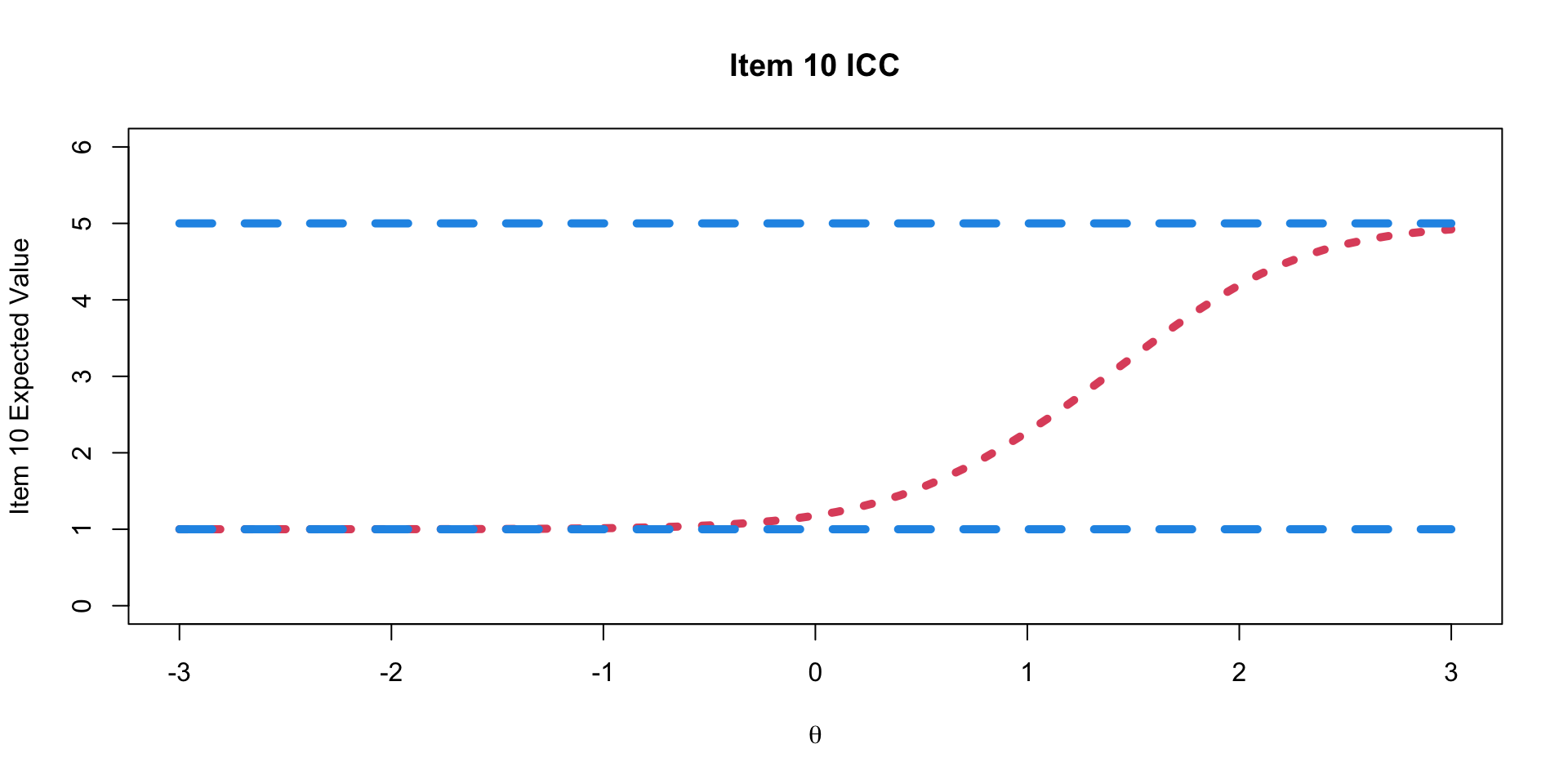
Graded Response Model Item Characteristic Curves
Investigating Latent Variables
Comparing Two Latent Variable Posterior Distributions
Comparing Latent Variable EAP Estimates with Posterior SDs
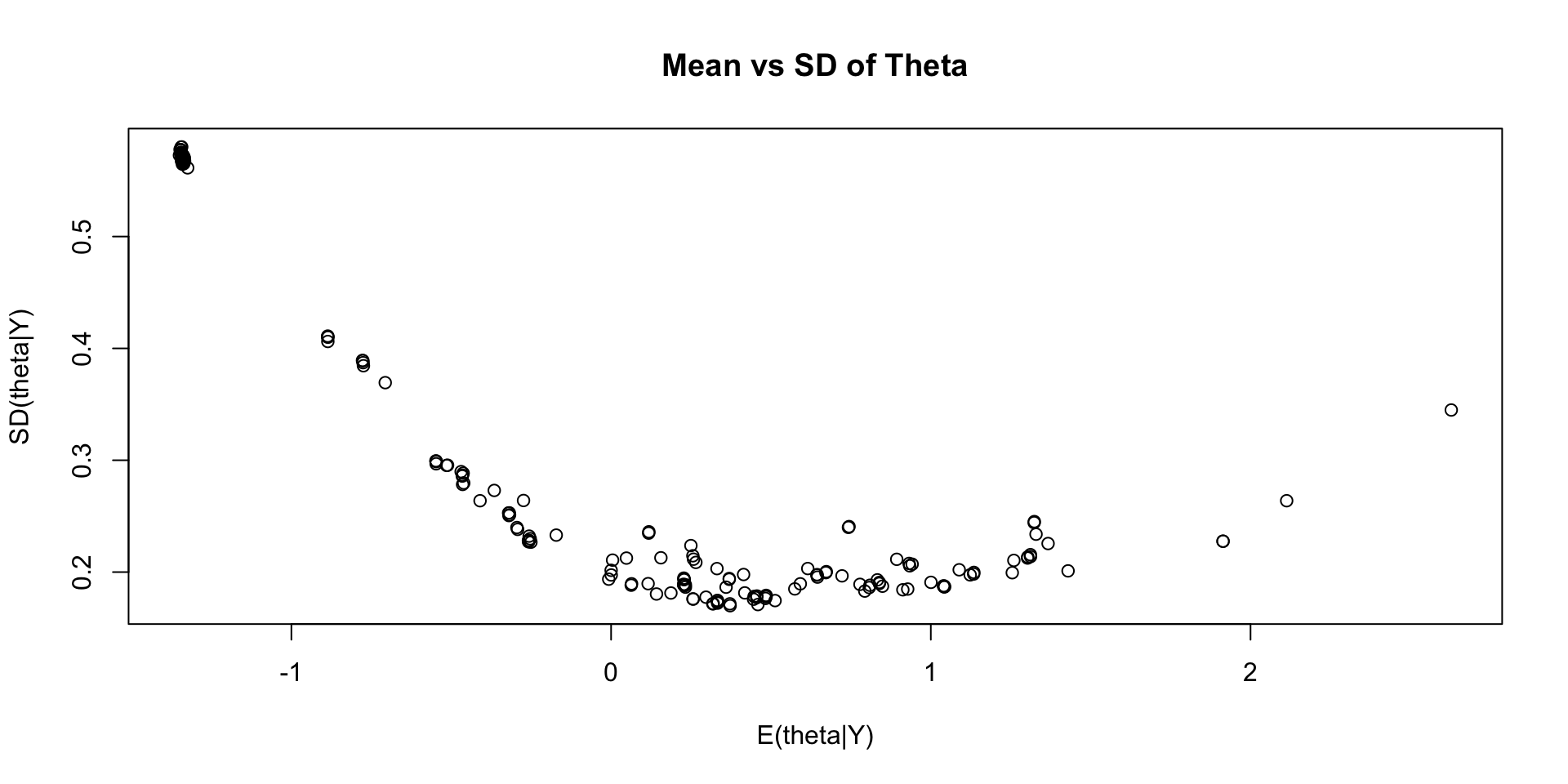
Comparing Latent Variable EAP Estimates with Sum Scores
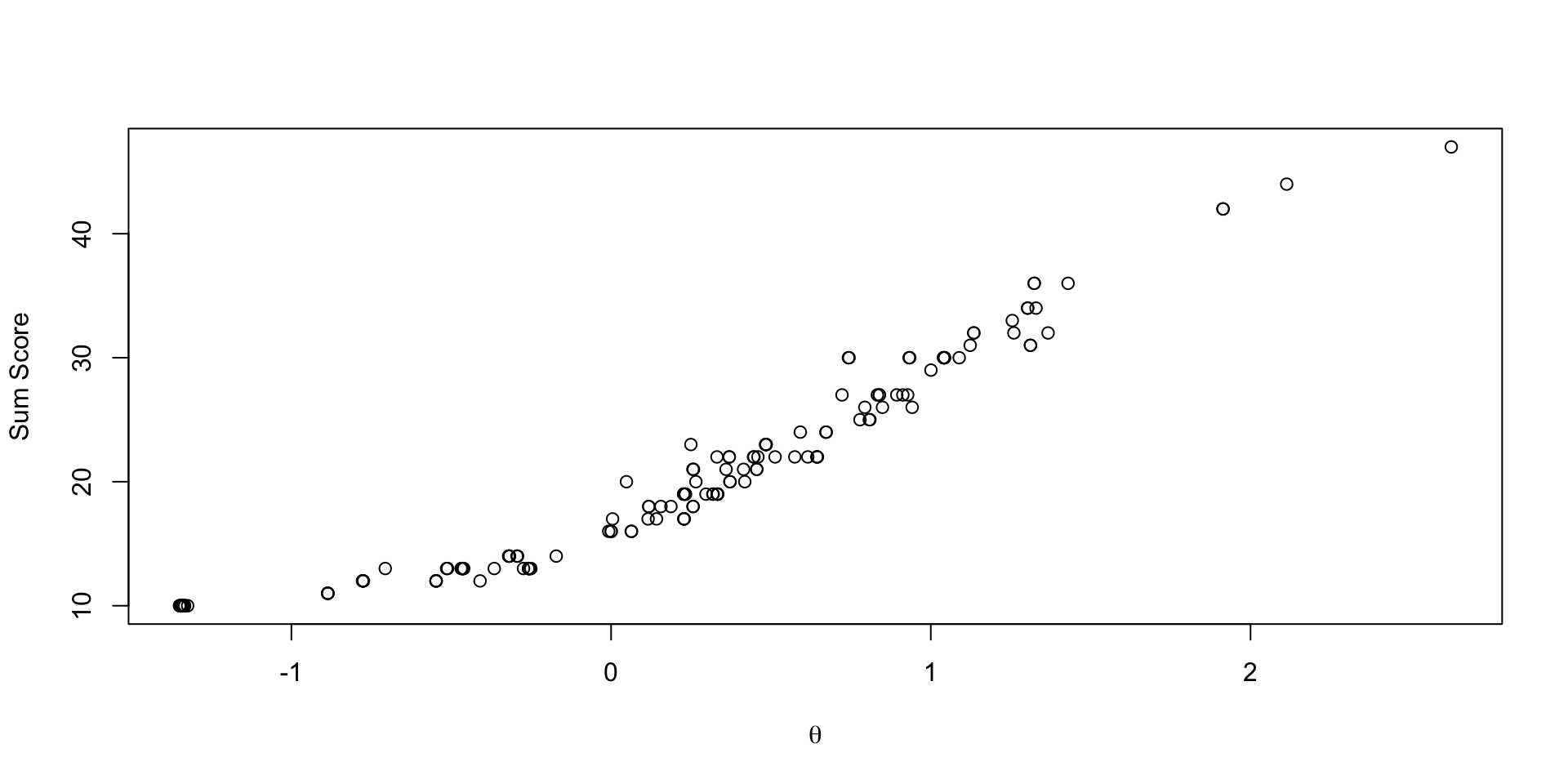
Comparing Latent Variable Posterior Means: GRM vs CFA
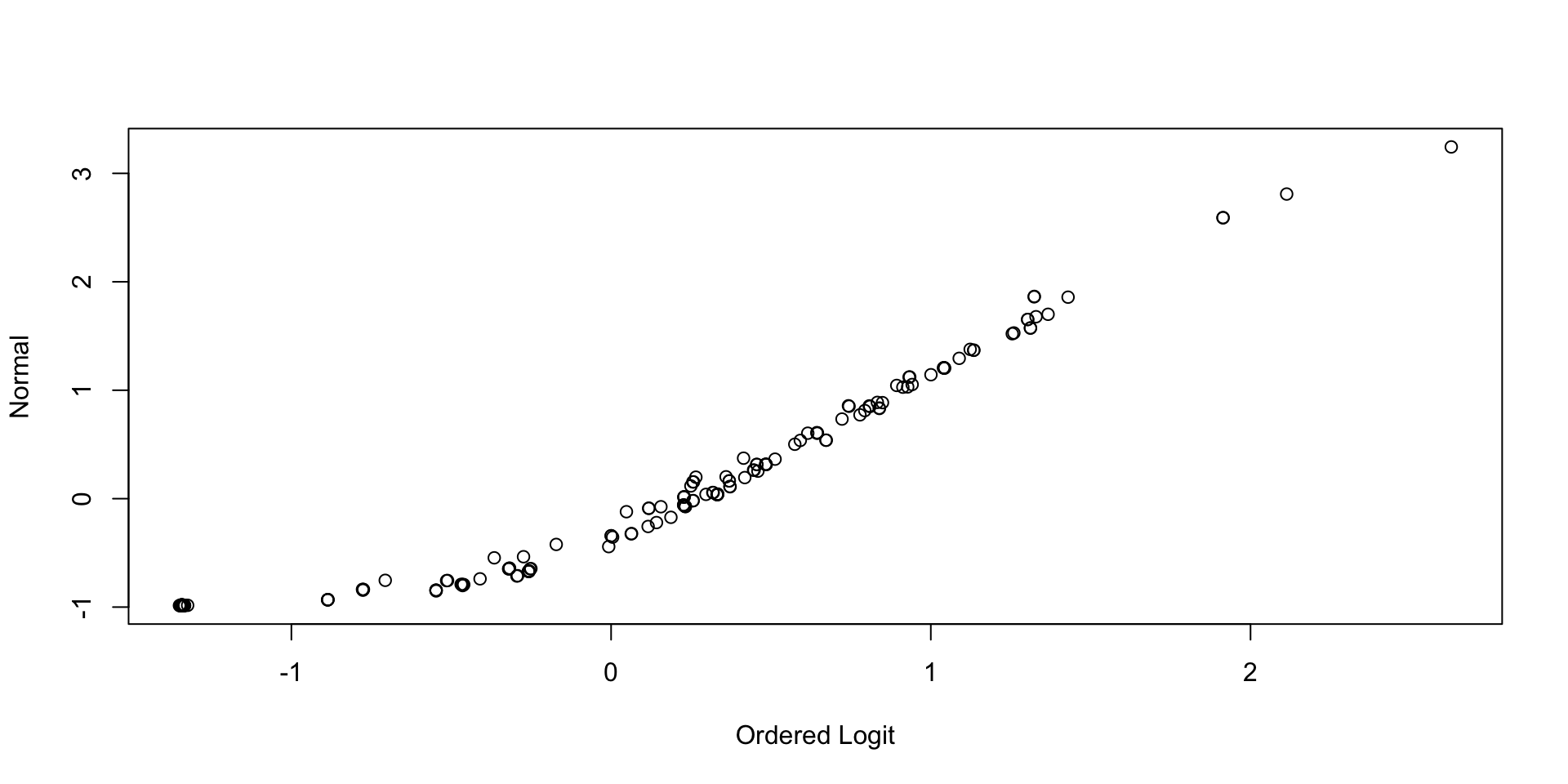
Comparing Latent Variable Posterior SDs: GRM vs Normal
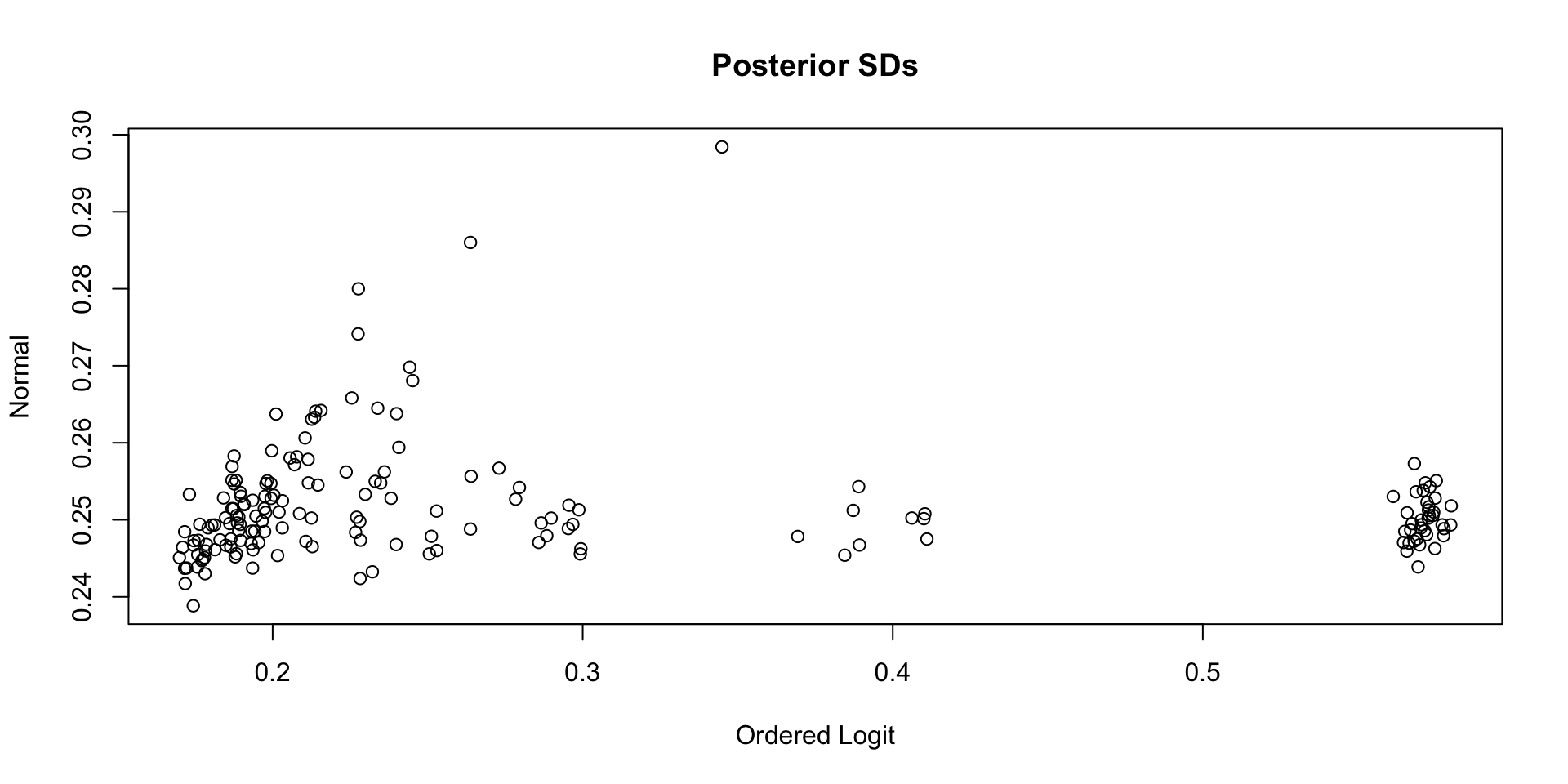
Which Posterior SD is Larger: GRM vs. CFA
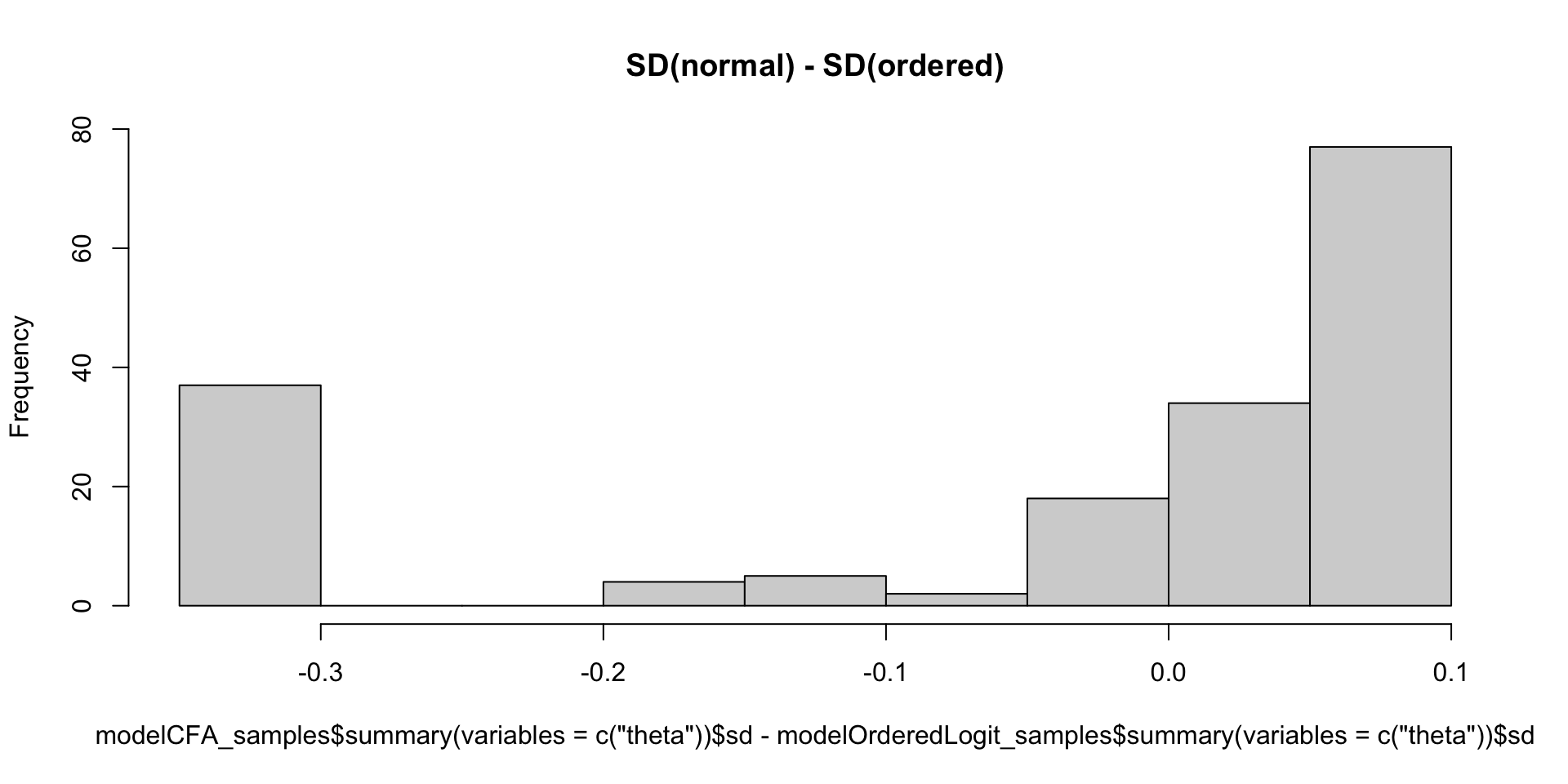
Comparing Thetas: GRM vs Binomial
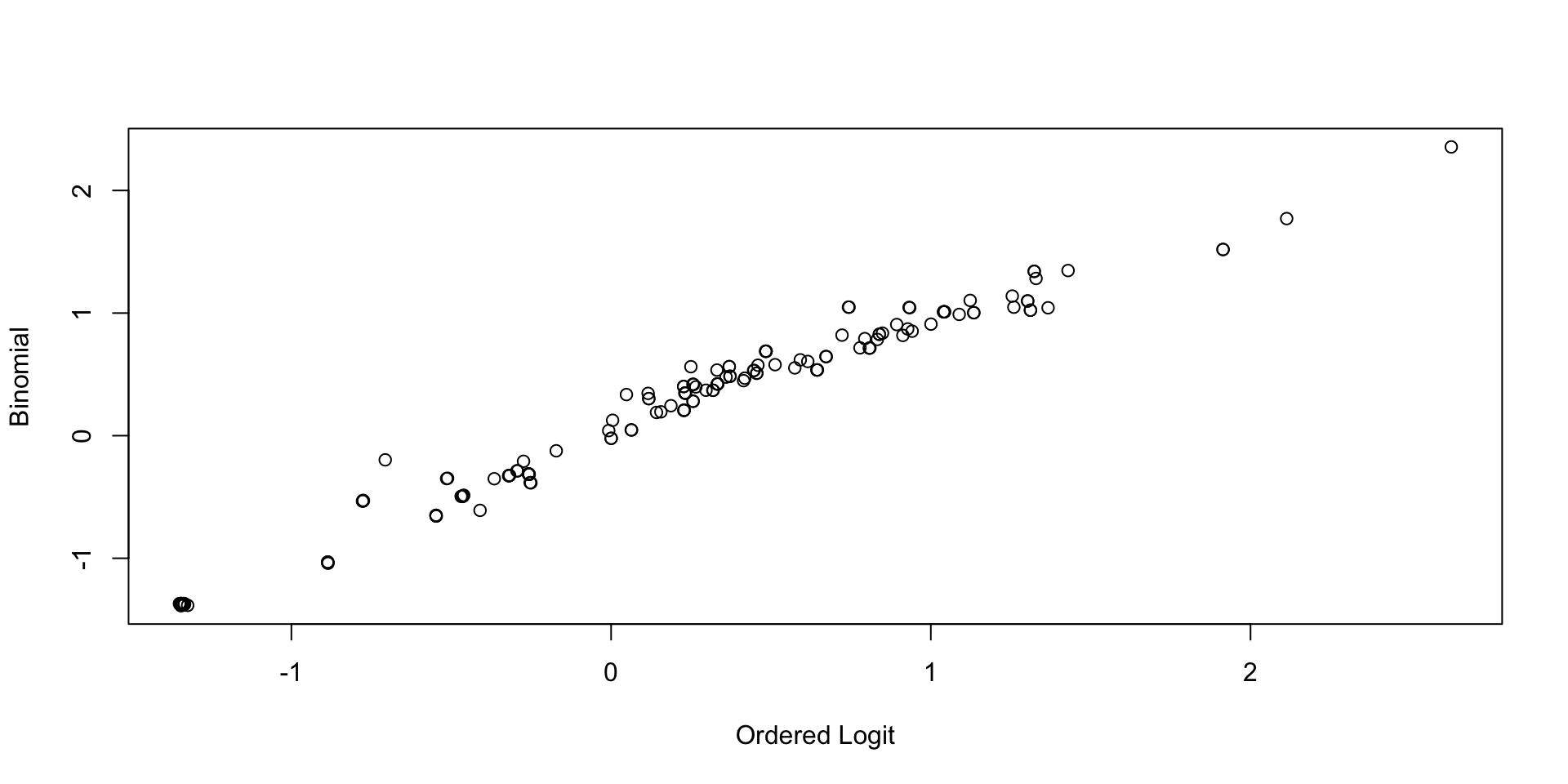
Comparing Latent Variable Posterior SDs: GRM vs Binomial
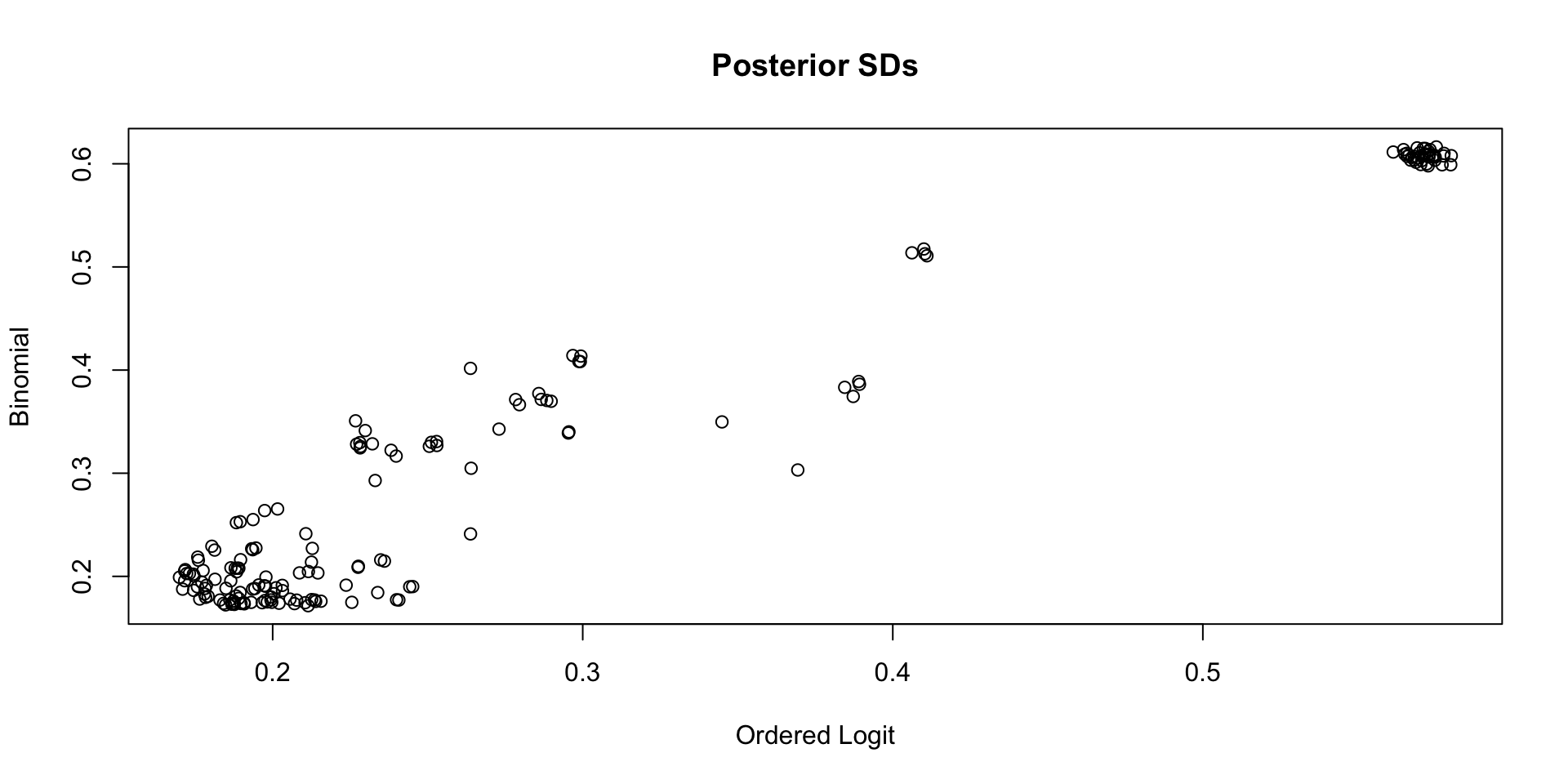
Which Posterior SD is Larger: GRM vs. Binomial
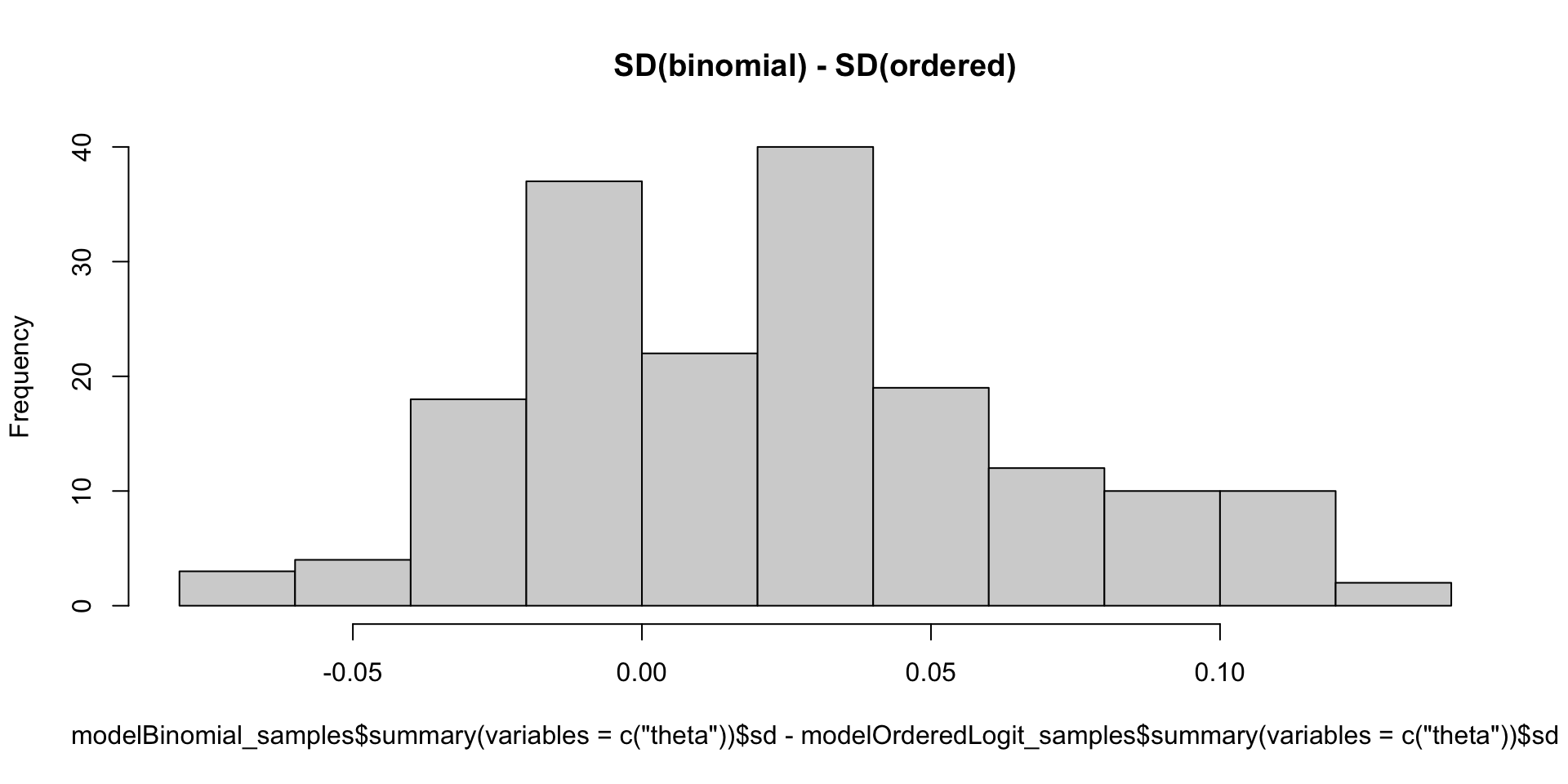
Nominal Response Models (Generalized Logit Models)
Adapting the Multinomial Distribution for Item Response Models
With some definitions, we can make a multinomial distribution into one we can use for polytomous item response models
- The number of “trials” is set to one for all items \(n_i=1\) (\(\forall i\))
- With \(n_i = 1\), this is called the categorical distribution
\[P(Y_{pi} \mid \theta_p) = p_{i1}^{I(y_{pi}=1)}\cdots p_{iC_i}^{I(y_{pi}=C_i)}\]
- The number of categories is equal to the number of options on an item (\(C_i\))
- The item response model is specified for the set of probabilities \(p_{ic}\), with \(\sum_c p_{ic}=1\)
- Then, use a link function to model each item’s set of \(p_{ic}\) as a function of the latent trait
Nominal Response Model (Generalized Logit Model)
The nominal response model is an ordered logistic regression model where:
\[P\left(Y_{ic } \mid \theta \right) = \frac{\exp(\mu_{ic}+\lambda_{ic}\theta_p)}{\sum_{c=1}^{C_i} \exp(\mu_{ic}+\lambda_{ic}\theta_p)}\]
Where:
- One constraint per parameter (one of these options):
- Sum to zero: \(\sum_{c=1}^{C_i} \mu_{ic} = 0\) and \(\sum_{c=1}^{C_i} \lambda_{ic} = 0\)
- Fix one category’s parameters to zero: \(\mu_{iC_{i}} = 0\) and \(\lambda_{iC_{i}} = 0\)
Estimating the NRM in Stan
model {
vector[maxCategory] probVec;
theta ~ normal(0,1);
for (item in 1:nItems){
initMu[item] ~ multi_normal(meanMu[item], covMu[item]); // Prior for item intercepts
initLambda[item] ~ multi_normal(meanLambda[item], covLambda[item]); // Prior for item loadings
for (obs in 1:nObs) {
for (category in 1:maxCategory){
probVec[category] = mu[item, category] + lambda[item, category]*theta[obs];
}
Y[item, obs] ~ categorical_logit(probVec);
}
}
}- Probability vector is built category-by-category
- Code is not vectorized (takes longer to run)
categorical_logitmodel takes input, applies inverse logit function, evaluates categorical distribution pmf- Set-to-zero constraints used:
initMuandinitLambdahave only estimated values in them- Will build
muandlambdain transformed parameters block
Nominal Response Model parameters Block
Set-to-zero constraints used:
initMuandinitLambdahave only estimated values in them- Will build
muandlambdain transformed parameters block
Nominal Response Model transformed parameters Block
transformed parameters {
array[nItems] vector[maxCategory] mu;
array[nItems] vector[maxCategory] lambda;
for (item in 1:nItems){
mu[item, 2:maxCategory] = initMu[item, 1:(maxCategory-1)];
mu[item, 1] = 0.0; // setting one category's intercept to zero
lambda[item, 2:maxCategory] = initLambda[item, 1:(maxCategory-1)];
lambda[item, 1] = 0.0; // setting one category's lambda to zero
}
}Notes:
- Here, we set the first category’s \(\mu_{i1}\) and \(\lambda_{i1}\) to zero
- We use
muandlambdafor the model itself (notinitMuorinitLambda)
Nominal Response Model data Block
data {
int maxCategory;
int nObs;
int nItems;
array[nItems, nObs] int Y;
array[nItems] vector[maxCategory-1] meanMu; // prior mean vector for intercept parameters
array[nItems] matrix[maxCategory-1, maxCategory-1] covMu; // prior covariance matrix for intercept parameters
array[nItems] vector[maxCategory-1] meanLambda; // prior mean vector for discrimination parameters
array[nItems] matrix[maxCategory-1, maxCategory-1] covLambda; // prior covariance matrix for discrimination parameters
}Almost the same as graded response model
- Lambda now needs an array
Nominal Response Model Data Preparation
# Data needs: successive integers from 1 to highest number (recode if not consistent)
maxCategory = 5
# data dimensions
nObs = nrow(conspiracyItems)
nItems = ncol(conspiracyItems)
# item threshold hyperparameters
muMeanHyperParameter = 0
muMeanVecHP = rep(muMeanHyperParameter, maxCategory-1)
muMeanMatrix = NULL
for (item in 1:nItems){
muMeanMatrix = rbind(muMeanMatrix, muMeanVecHP)
}
muVarianceHyperParameter = 1000
muCovarianceMatrixHP = diag(x = muVarianceHyperParameter, nrow = maxCategory-1)
muCovArray = array(data = 0, dim = c(nItems, maxCategory-1, maxCategory-1))
for (item in 1:nItems){
muCovArray[item, , ] = diag(x = muVarianceHyperParameter, nrow = maxCategory-1)
}
# item discrimination/factor loading hyperparameters
lambdaMeanHyperParameter = 0
lambdaMeanVecHP = rep(lambdaMeanHyperParameter, maxCategory-1)
lambdaMeanMatrix = NULL
for (item in 1:nItems){
lambdaMeanMatrix = rbind(lambdaMeanMatrix, lambdaMeanVecHP)
}
lambdaVarianceHyperParameter = 1000
lambdaCovarianceMatrixHP = diag(x = lambdaVarianceHyperParameter, nrow = maxCategory-1)
lambdaCovArray = array(data = 0, dim = c(nItems, maxCategory-1, maxCategory-1))
for (item in 1:nItems){
lambdaCovArray[item, , ] = diag(x = lambdaVarianceHyperParameter, nrow = maxCategory-1)
}
modelOrderedLogit_data = list(
nObs = nObs,
nItems = nItems,
maxCategory = maxCategory,
maxItem = maxItem,
Y = t(conspiracyItems),
meanMu = muMeanMatrix,
covMu = muCovArray,
meanLambda = lambdaMeanMatrix,
covLambda = lambdaCovArray
)Nominal Response Model Stan Call
Nominal Response Model Results
[1] 1.005476# A tibble: 100 × 10
variable mean median sd mad q5 q95 rhat ess_bulk
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu[1,1] 0 0 0 0 0 0 NA NA
2 mu[2,1] 0 0 0 0 0 0 NA NA
3 mu[3,1] 0 0 0 0 0 0 NA NA
4 mu[4,1] 0 0 0 0 0 0 NA NA
5 mu[5,1] 0 0 0 0 0 0 NA NA
6 mu[6,1] 0 0 0 0 0 0 NA NA
7 mu[7,1] 0 0 0 0 0 0 NA NA
8 mu[8,1] 0 0 0 0 0 0 NA NA
9 mu[9,1] 0 0 0 0 0 0 NA NA
10 mu[10,1] 0 0 0 0 0 0 NA NA
11 mu[1,2] 1.06 1.06 0.294 0.287 0.588 1.56 1.00 1611.
12 mu[2,2] 0.369 0.369 0.251 0.254 -0.0311 0.793 1.00 2166.
13 mu[3,2] -0.494 -0.492 0.265 0.263 -0.931 -0.0611 1.00 2402.
14 mu[4,2] 0.561 0.558 0.278 0.281 0.113 1.02 1.00 1795.
15 mu[5,2] 0.646 0.642 0.264 0.265 0.224 1.09 1.00 2166.
16 mu[6,2] 0.641 0.631 0.285 0.284 0.189 1.12 1.00 1827.
17 mu[7,2] -0.311 -0.308 0.241 0.238 -0.713 0.0873 1.00 2368.
18 mu[8,2] 0.321 0.319 0.268 0.273 -0.122 0.762 1.00 2019.
19 mu[9,2] -0.345 -0.347 0.242 0.239 -0.734 0.0552 1.00 2026.
20 mu[10,2] -1.46 -1.45 0.258 0.260 -1.89 -1.05 1.00 3373.
21 mu[1,3] 0.934 0.927 0.306 0.310 0.433 1.44 1.00 1600.
22 mu[2,3] -0.740 -0.734 0.375 0.368 -1.37 -0.138 1.00 1764.
23 mu[3,3] -0.218 -0.216 0.260 0.261 -0.650 0.211 1.00 1979.
24 mu[4,3] 0.138 0.143 0.341 0.336 -0.428 0.682 1.00 1553.
25 mu[5,3] -0.630 -0.623 0.415 0.414 -1.31 0.0465 1.00 1687.
26 mu[6,3] -0.0531 -0.0555 0.359 0.360 -0.644 0.540 1.00 1615.
27 mu[7,3] -1.16 -1.15 0.346 0.339 -1.75 -0.619 1.00 2428.
28 mu[8,3] -0.218 -0.216 0.352 0.355 -0.804 0.357 1.00 1674.
29 mu[9,3] -1.72 -1.70 0.410 0.397 -2.43 -1.08 1.00 2235.
30 mu[10,3] -2.37 -2.35 0.400 0.384 -3.06 -1.76 1.00 3201.
31 mu[1,4] 0.289 0.280 0.325 0.321 -0.236 0.824 1.00 2056.
32 mu[2,4] -1.13 -1.12 0.362 0.355 -1.72 -0.545 1.00 3048.
33 mu[3,4] -1.90 -1.89 0.400 0.395 -2.58 -1.27 1.00 3521.
34 mu[4,4] -1.32 -1.32 0.428 0.429 -2.03 -0.628 1.00 3093.
35 mu[5,4] -0.765 -0.756 0.373 0.371 -1.38 -0.168 1.00 2350.
36 mu[6,4] -1.10 -1.09 0.425 0.413 -1.83 -0.424 1.00 2820.
37 mu[7,4] -1.94 -1.92 0.400 0.384 -2.64 -1.31 1.00 3408.
38 mu[8,4] -1.78 -1.77 0.453 0.453 -2.55 -1.06 0.999 3917.
39 mu[9,4] -1.42 -1.42 0.333 0.326 -1.96 -0.887 1.00 2436.
40 mu[10,4] -3.26 -3.23 0.474 0.458 -4.06 -2.51 1.00 5046.
41 mu[1,5] -0.984 -0.965 0.459 0.460 -1.75 -0.261 1.00 2367.
42 mu[2,5] -1.50 -1.48 0.401 0.396 -2.18 -0.853 1.00 3037.
43 mu[3,5] -1.96 -1.94 0.428 0.423 -2.69 -1.28 1.00 3820.
44 mu[4,5] -1.07 -1.06 0.398 0.391 -1.74 -0.422 1.00 2662.
45 mu[5,5] -1.38 -1.37 0.433 0.430 -2.11 -0.705 1.00 2888.
46 mu[6,5] -1.77 -1.75 0.494 0.478 -2.61 -1.01 1.00 3460.
47 mu[7,5] -2.31 -2.29 0.450 0.443 -3.09 -1.61 1.00 3774.
48 mu[8,5] -2.13 -2.11 0.503 0.474 -3.00 -1.34 1.00 4103.
49 mu[9,5] -1.91 -1.89 0.393 0.385 -2.59 -1.30 1.00 3329.
50 mu[10,5] -2.21 -2.19 0.335 0.332 -2.79 -1.68 1.00 3980.
51 lambda[1,1] 0 0 0 0 0 0 NA NA
52 lambda[2,1] 0 0 0 0 0 0 NA NA
53 lambda[3,1] 0 0 0 0 0 0 NA NA
54 lambda[4,1] 0 0 0 0 0 0 NA NA
55 lambda[5,1] 0 0 0 0 0 0 NA NA
56 lambda[6,1] 0 0 0 0 0 0 NA NA
57 lambda[7,1] 0 0 0 0 0 0 NA NA
58 lambda[8,1] 0 0 0 0 0 0 NA NA
59 lambda[9,1] 0 0 0 0 0 0 NA NA
60 lambda[10,1] 0 0 0 0 0 0 NA NA
61 lambda[1,2] 1.19 1.18 0.232 0.235 0.818 1.58 1.00 1625.
62 lambda[2,2] 1.33 1.33 0.248 0.238 0.943 1.75 1.00 2510.
63 lambda[3,2] 1.59 1.58 0.286 0.287 1.14 2.08 1.00 3188.
64 lambda[4,2] 1.75 1.74 0.293 0.294 1.29 2.24 1.00 2499.
65 lambda[5,2] 1.60 1.59 0.278 0.280 1.16 2.08 1.00 2033.
66 lambda[6,2] 2.05 2.04 0.314 0.311 1.54 2.58 1.00 2434.
67 lambda[7,2] 1.44 1.43 0.275 0.269 1.00 1.91 1.00 2815.
68 lambda[8,2] 1.68 1.67 0.295 0.290 1.22 2.19 1.00 2999.
69 lambda[9,2] 1.36 1.35 0.268 0.260 0.933 1.82 1.00 2823.
70 lambda[10,2] 1.24 1.23 0.275 0.267 0.811 1.71 1.00 3095.
71 lambda[1,3] 1.91 1.92 0.282 0.284 1.46 2.39 1.00 1829.
72 lambda[2,3] 2.79 2.77 0.411 0.408 2.15 3.50 1.00 2100.
73 lambda[3,3] 1.81 1.80 0.291 0.288 1.35 2.31 1.00 2880.
74 lambda[4,3] 2.80 2.78 0.389 0.393 2.20 3.46 1.00 2202.
75 lambda[5,3] 3.36 3.34 0.436 0.434 2.66 4.10 1.00 2161.
76 lambda[6,3] 3.12 3.10 0.404 0.405 2.47 3.80 1.00 2561.
77 lambda[7,3] 2.28 2.26 0.377 0.372 1.70 2.92 1.00 2535.
78 lambda[8,3] 3.08 3.05 0.440 0.430 2.39 3.83 1.00 2402.
79 lambda[9,3] 2.53 2.52 0.415 0.413 1.88 3.24 1.00 2158.
80 lambda[10,3] 1.82 1.80 0.367 0.363 1.25 2.43 1.00 3025.
81 lambda[1,4] 1.45 1.44 0.291 0.292 0.987 1.94 0.999 1964.
82 lambda[2,4] 1.86 1.85 0.405 0.409 1.23 2.54 1.00 3086.
83 lambda[3,4] 1.60 1.58 0.420 0.421 0.921 2.29 1.00 3708.
84 lambda[4,4] 1.91 1.89 0.468 0.466 1.15 2.69 1.00 3558.
85 lambda[5,4] 2.27 2.25 0.431 0.421 1.59 3.02 1.00 3055.
86 lambda[6,4] 2.31 2.30 0.477 0.474 1.54 3.10 1.00 2994.
87 lambda[7,4] 1.63 1.63 0.426 0.417 0.946 2.34 1.00 3333.
88 lambda[8,4] 1.92 1.90 0.533 0.540 1.05 2.83 1.00 3003.
89 lambda[9,4] 1.56 1.55 0.365 0.366 0.981 2.16 1.00 3144.
90 lambda[10,4] 0.850 0.837 0.458 0.477 0.117 1.61 1.00 4696.
91 lambda[1,5] 2.06 2.05 0.421 0.425 1.38 2.76 1.00 2617.
92 lambda[2,5] 1.79 1.77 0.453 0.470 1.07 2.55 1.00 2984.
93 lambda[3,5] 1.77 1.76 0.430 0.436 1.08 2.50 1.00 2871.
94 lambda[4,5] 1.75 1.74 0.428 0.432 1.07 2.46 1.00 2804.
95 lambda[5,5] 2.10 2.10 0.505 0.498 1.28 2.92 1.00 2638.
96 lambda[6,5] 2.09 2.09 0.554 0.565 1.19 3.02 1.00 3460.
97 lambda[7,5] 1.57 1.56 0.470 0.463 0.816 2.36 1.00 2408.
98 lambda[8,5] 1.59 1.58 0.549 0.547 0.704 2.50 1.00 3112.
99 lambda[9,5] 1.47 1.45 0.419 0.407 0.802 2.20 1.00 3226.
100 lambda[10,5] 1.25 1.24 0.346 0.338 0.705 1.82 1.00 3160.
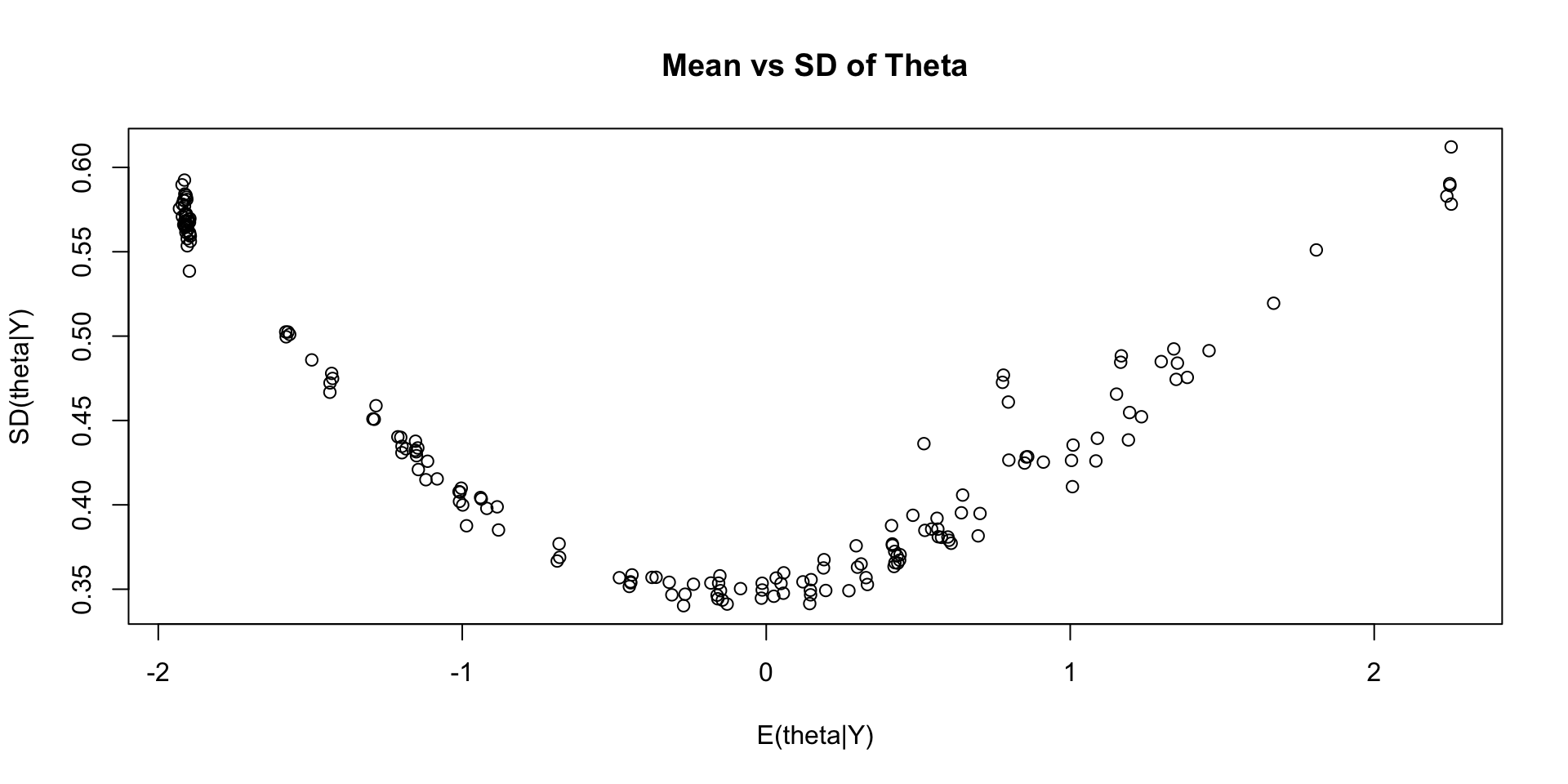
# … with 1 more variable: ess_tail <dbl>Comparing EAP Estimates with Posterior SDs
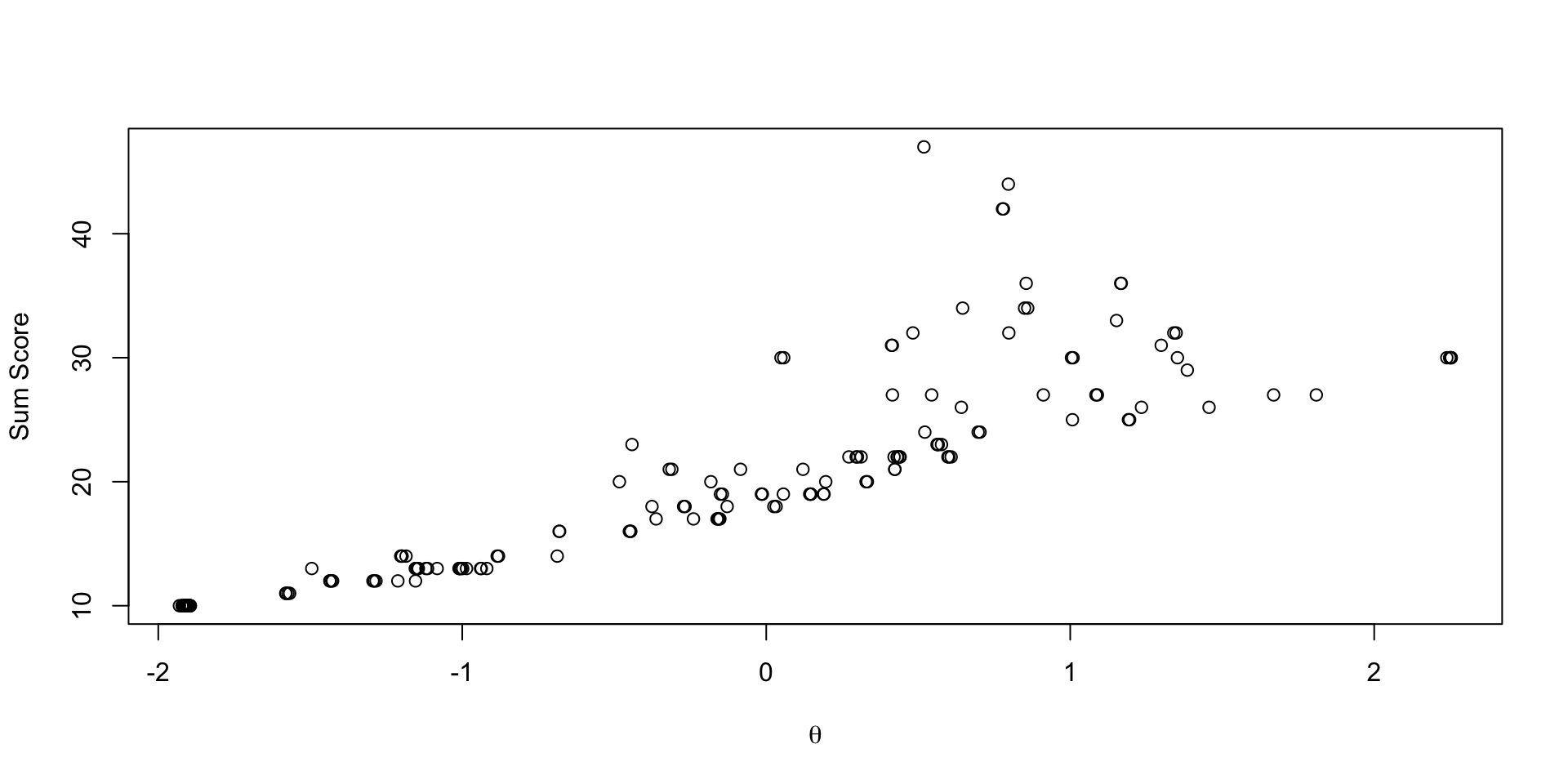
Comparing EAP Estimates with Sum Scores
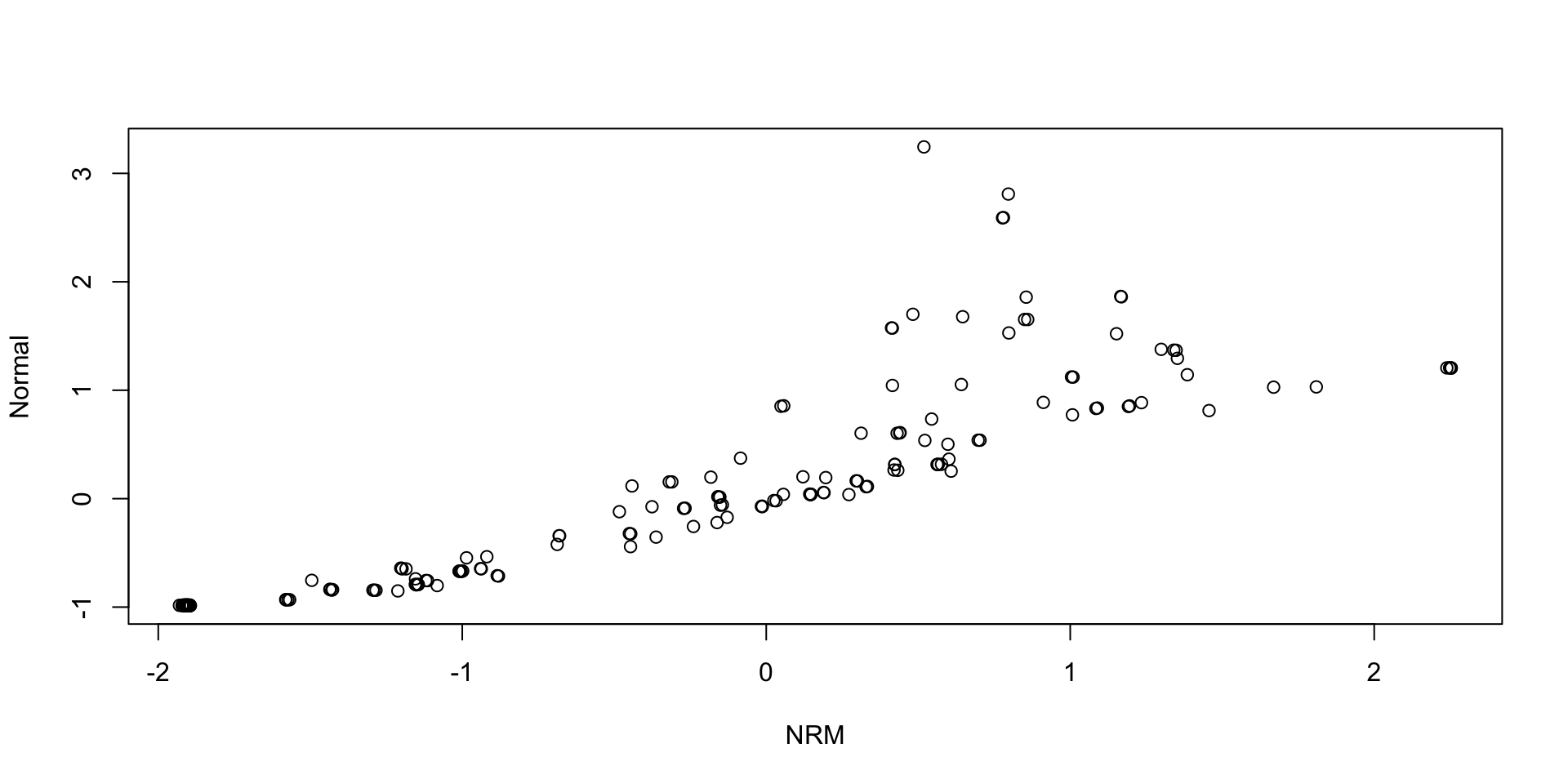
Comparing Thetas: NRM vs Normal:
Comparing Theta SDs: NRM vs Normal:
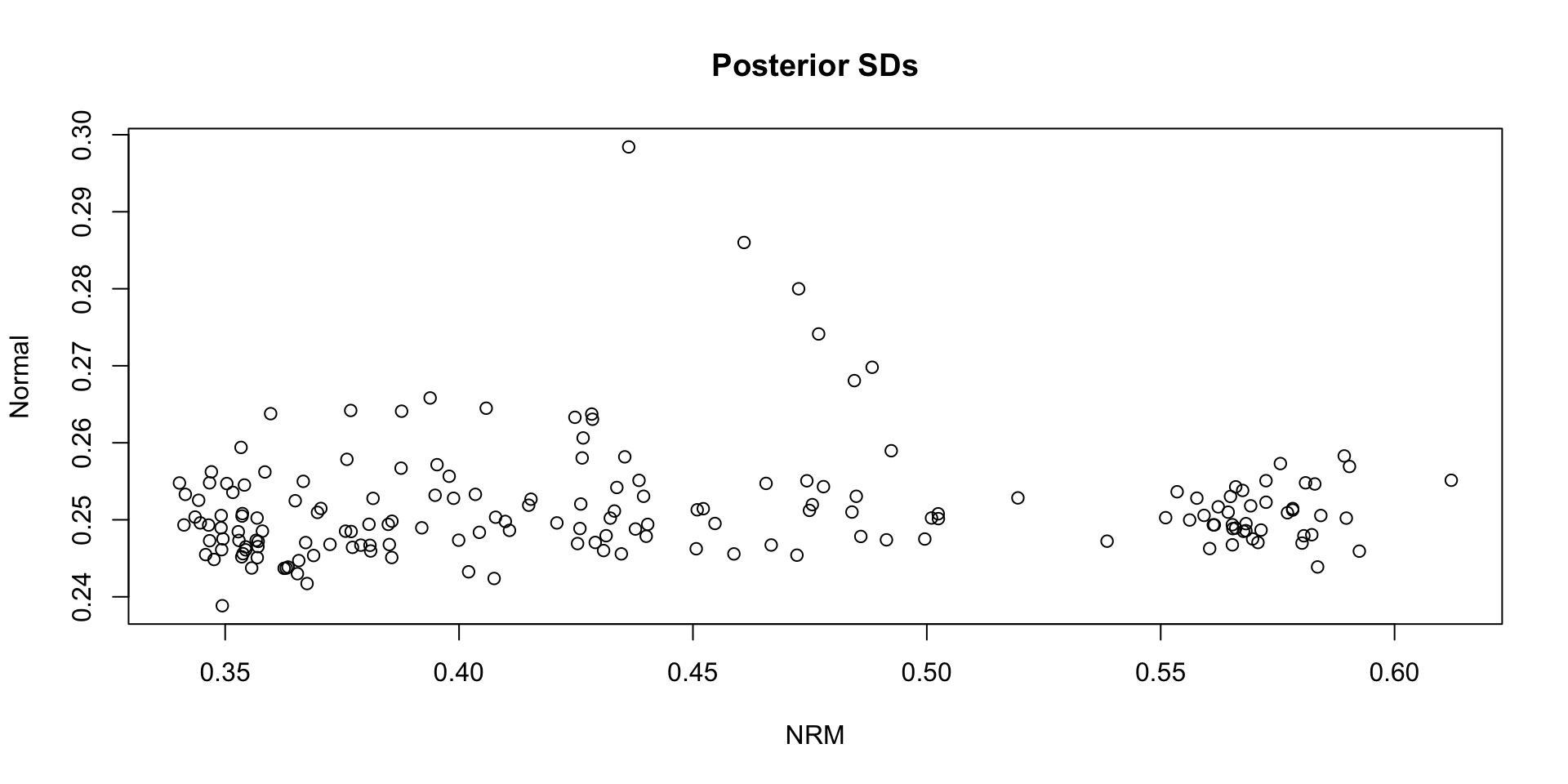
Which SDs are bigger: NRM vs. Normal?
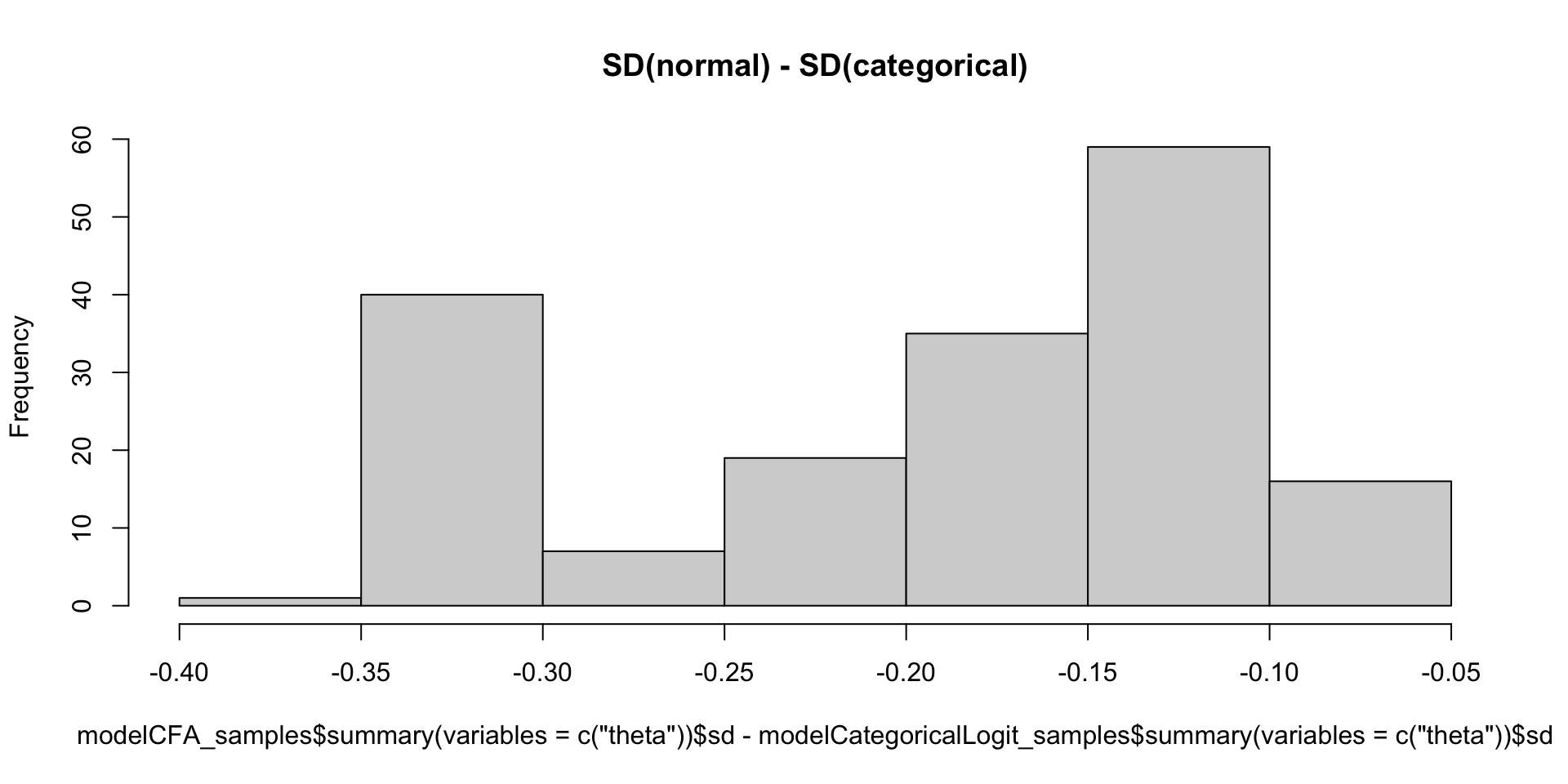
Comparing Thetas: NRM vs GRM:
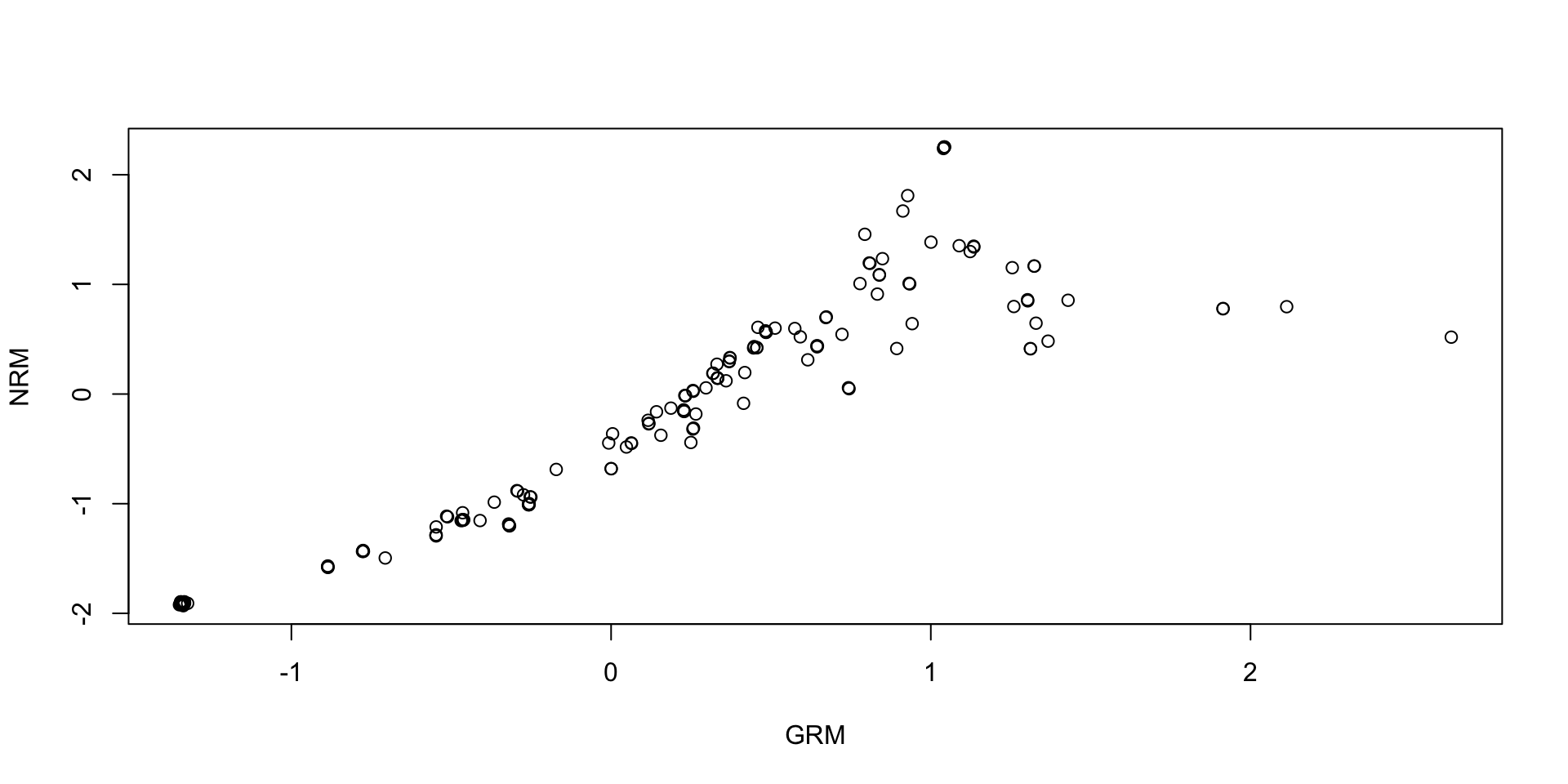
Comparing Theta SDs: NRM vs GRM:
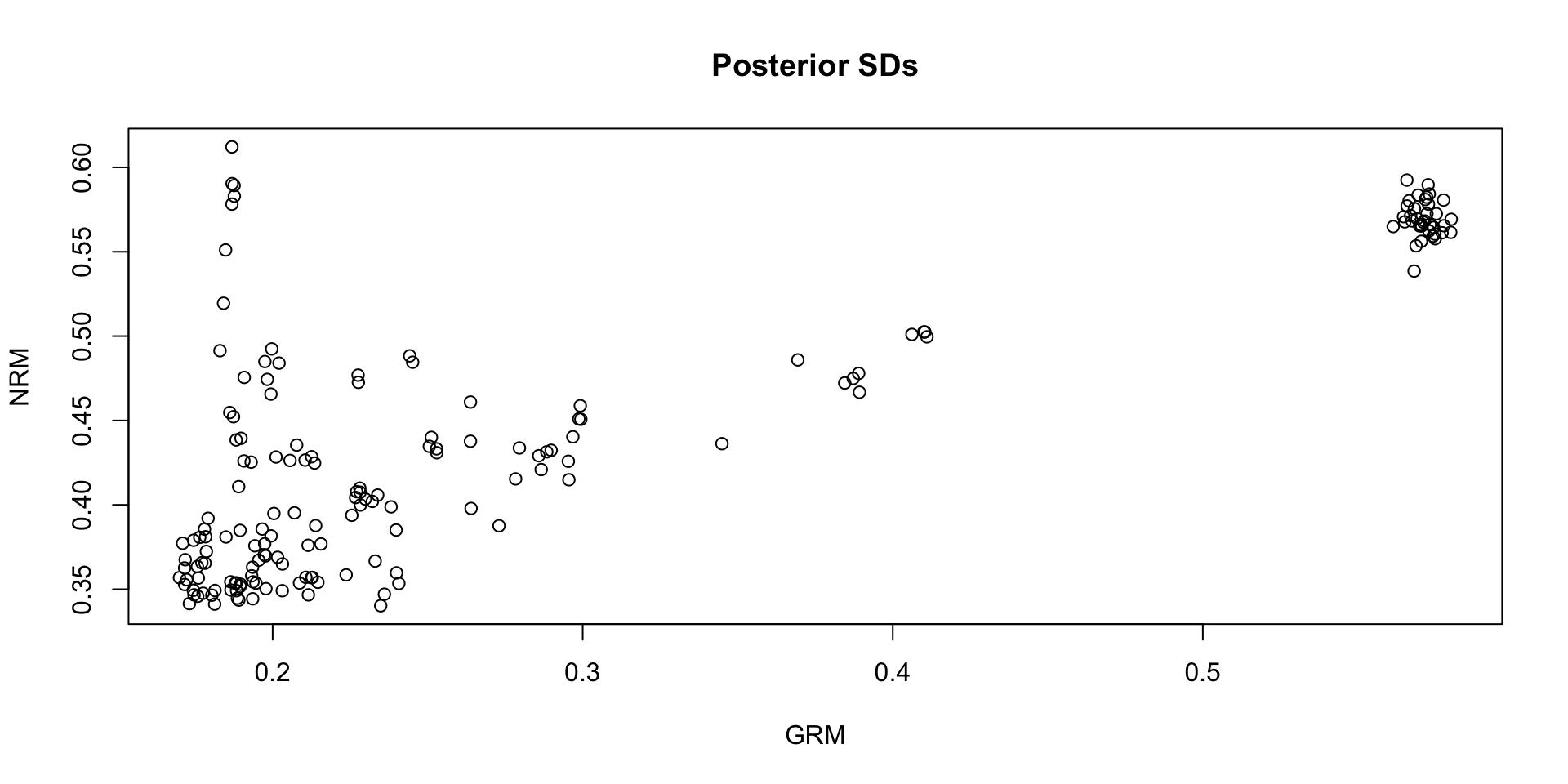
Which SDs are bigger: NRM vs GRM?
Models With Different Types of Items
Models with Different Types of Items
Although often taught as one type of model that applies to all items, you can mix-and-match distributions
- Recall the posterior distribution of the latent variable \(\theta_p\)
- For each person, the model (data) likelihood function can be constructed so that each item’s conditional PDF is used:
\[f \left(\boldsymbol{Y}_{p} \mid \theta_p \right) = \prod_{i=1}^If \left(Y_{pi} \mid \theta_p \right)\]
Here, \(\prod_{i=1}^If \left(Y_{pi} \mid \theta_p \right)\) can be any distribution that you can build
Wrapping Up
Wrapping Up
- There are many different models for polytomous data
- Almost all use the categorical (multinomial with one trial) distribution
- What we say today is that the posterior SDs of the latent variables are larger with categorical models
- Much more uncertainty compared to normal models
- What we will need is model fit information to determine what fits best